Learn the six core components of a data quality framework and how they work together to ensure reliable data.
Table of Contents
Like this article?
Follow our monthly digest to get more educational content like this.

Modern data platforms often rely on dozens, or even hundreds, of pipelines moving data between systems. As datasets and transformations grow in number and sets get bigger, maintaining consistent validation across the platform becomes harder.
A data quality (DQ) framework is a set of principles, standards, processes, and tools used to monitor and manage your organization’s data. It provides a structured way to manage your data’s complexity by replacing scattered validation scripts and ad hoc checks with consistent expectations, continuous monitoring, and defined processes for handling anomalies. It acts as the operational layer that connects governance policies with the technical checks used to enforce them across data pipelines.
Without the structure provided by a framework, data quality efforts tend to become reactive, with issues only discovered after they impact downstream systems. A well-defined framework shifts this approach toward repeatable workflows and clearer ownership, making it easier to manage data quality at scale.
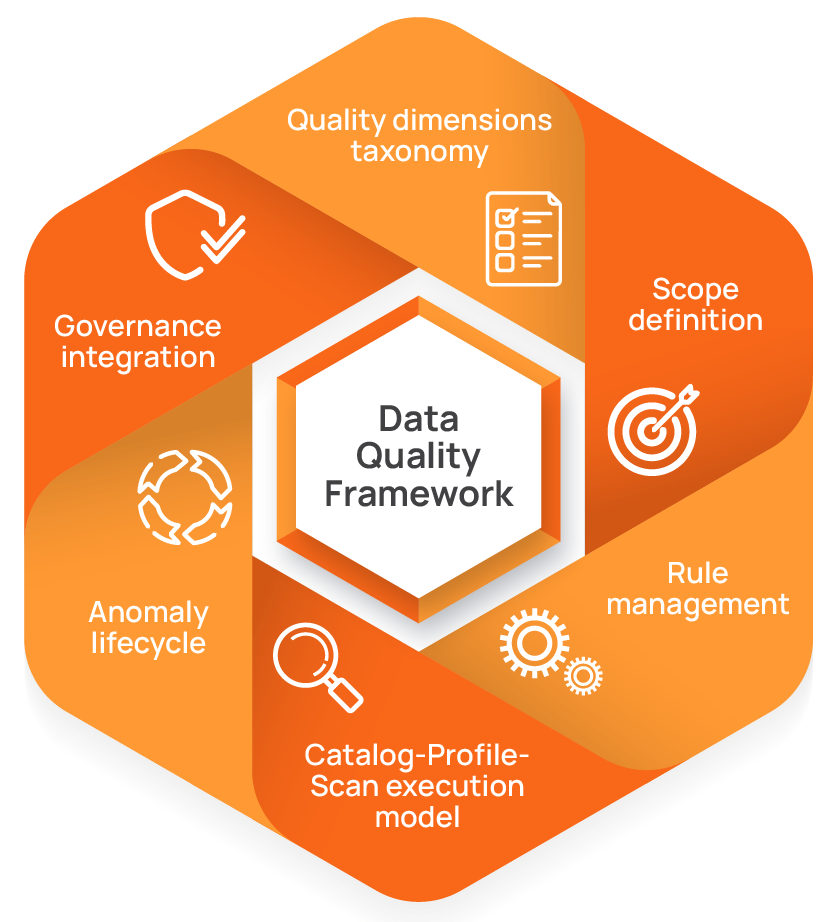
Most data quality frameworks are built around six core components: a quality dimensions taxonomy, scope definition, rule management, a catalog-profile-scan execution model, an anomaly lifecycle, and governance integration. Each component addresses a different part of the data quality process, from defining what “good data” looks like to ensuring that issues are detected and resolved consistently. The following sections explain how these components work together to support reliable data pipelines.
Summary of key data quality framework concepts
The following capabilities form the operational foundation of a data quality framework.
{{banner-large-1="/banners"}}
Quality dimensions taxonomy
Data quality dimensions give teams a structured way to evaluate whether a dataset is actually usable. Instead of treating quality as something abstract, they break it down into measurable characteristics that can be applied consistently.
Each dimension represents a different characteristic of data quality that can be measured and monitored. Common dimensions include accuracy, completeness, consistency, volumetrics, timeliness, conformity, precision, and coverage. For a more detailed breakdown of these dimensions, see the data quality dimensions article.
Using these dimensions creates a shared language. Engineers, analysts, and data stewards can describe issues using the same terms, which reduces confusion during debugging or incident analysis. This becomes especially valuable in organizations where data flows across multiple teams and systems. They also help guide how validation rules are designed. For example, a null check aligns with completeness, while a freshness check aligns with timeliness. Without this structure, rules tend to be defined inconsistently, making it harder to reason about overall data quality.
Over time, these dimensions can also be used to measure trends. For example, teams might track completeness rates or consistency violations across datasets. This allows them to identify recurring issues, measure improvements, and prioritize fixes based on impact. In more mature setups, these metrics feed into dashboards or quality scores, giving teams a clearer picture of how data quality evolves over time.
Structuring rules around dimensions helps ensure consistency and makes rule libraries easier to maintain over time. In more mature implementations, these dimensions can also be used to track quality metrics and trends over time.
Scope definition
Scope definition determines which datasets, tables, and fields require data quality monitoring and where validation should be applied across the data pipeline. This step is often underestimated, but it has a direct impact on how effective the entire framework will be.
Traditionally, scope has been constrained by engineering effort. In large environments, monitoring everything manually doesn’t scale: As the number of datasets grows, so does the effort required to maintain rules and ensure coverage, forcing teams to prioritize only a subset of data.
Automation changes this dynamic. Some platforms can automatically suggest a large portion of the validation rules needed, often covering common scenarios based on observed data patterns. For example, platforms like Qualytics use inference engines to automatically generate up to 95% of the validation rules required for a dataset, enabling teams to significantly expand monitoring coverage without relying entirely on manual rule definition.
Automation shifts how teams approach scope. Instead of asking what’s realistic to monitor, the question becomes how to manage and act on findings at scale. With automation, teams can monitor far more data than before.
However, automation introduces a new challenge: alert fatigue. No one wants to start their day with hundreds of alerts, most of which don’t actually matter. To address this, teams rely on prioritization strategies such as severity scoring, tagging, and ownership rather than limiting monitoring scope. This allows them to maintain broad visibility across datasets while focusing attention on the most critical issues.
Scope is not only about what to monitor but also where validation should occur. Applying validation close to ingestion—often referred to as using a shift-left approach—helps you detect issues before they propagate downstream. Discovering and remediating problems early in the process is almost always easier. No one enjoys tracing a broken value through five downstream transformations to figure out where it went wrong.
In practice, teams often begin by using a data catalog to inventory datasets, schemas, and metadata. Profiling then helps identify patterns such as null rates, value distributions, or unexpected changes. These insights guide which fields need validation and what types of rules should be applied.
Building on this, while monitoring is applied broadly across datasets, issues are prioritized based on their importance and impact. Business critical datasets such as those used in financial reporting or customer analytics are assigned higher priority, with stricter validation and faster response times. Less critical datasets are still monitored but with lower priority or lighter alerting thresholds to avoid unnecessary noise.
Rule management
Validation rules define the conditions a dataset must meet to be considered reliable. These rules generally fall into three categories:
- Inferred rules are generated automatically based on observed data patterns, using statistical profiling or machine learning techniques. Not all platforms support this capability, and those that do vary in how much of the required validation logic can be inferred. In such systems, a significant portion of rules (such as completeness or distribution checks) can be created without manual configuration, reducing the effort required to establish baseline data quality coverage.
- Templated rules, in contrast, are prebuilt validation patterns—such as null checks, range validation, or uniqueness constraints—that engineers configure manually based on their needs. In platforms without strong inference capabilities, most validation rules are created using these templates.
- Custom rules extend beyond generic validation patterns by capturing domain-specific logic and relationships between fields. These rules reflect how the business operates, such as validating transaction logic or enforcing constraints specific to a particular use case.
To illustrate how validation rules are implemented in practice, the following example demonstrates how a templated rule pattern can be applied to a specific dataset.
Templated rules define reusable validation logic that can be applied across different datasets and fields. A common example is a null-check pattern, where the same structure is reused to detect missing values in different columns.
A generic version of this template can be defined as:
SELECT COUNT(*) - COUNT({column_name}) AS null_count
FROM {table_name};
This template becomes a concrete validation rule when applied to a specific dataset and column:
SELECT COUNT(*) - COUNT(order_amount) AS null_count
FROM sales_data;
This example shows how a reusable templated pattern is instantiated into an executable rule to detect unexpected null values in the order_amount column.
As the number of rules grows, things can get difficult to manage without some structure in place. Teams may end up duplicating rules or applying inconsistent logic across datasets. Centralizing rules into a shared library helps address this by making it easier to reuse validation logic, maintain consistency, and avoid redundant rule definitions.
A typical lifecycle looks like this:
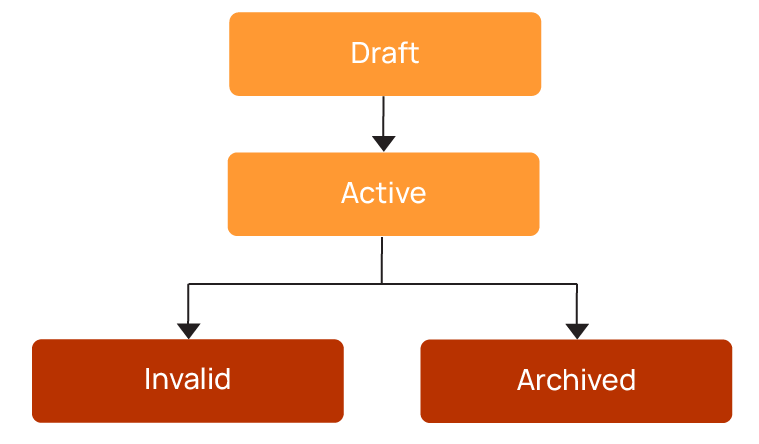
It’s often desirable for rules to follow a structured lifecycle, where they are first created and tested in a draft state before being activated once validated. Over time, some rules may be retired or invalidated as data structures or requirements change.
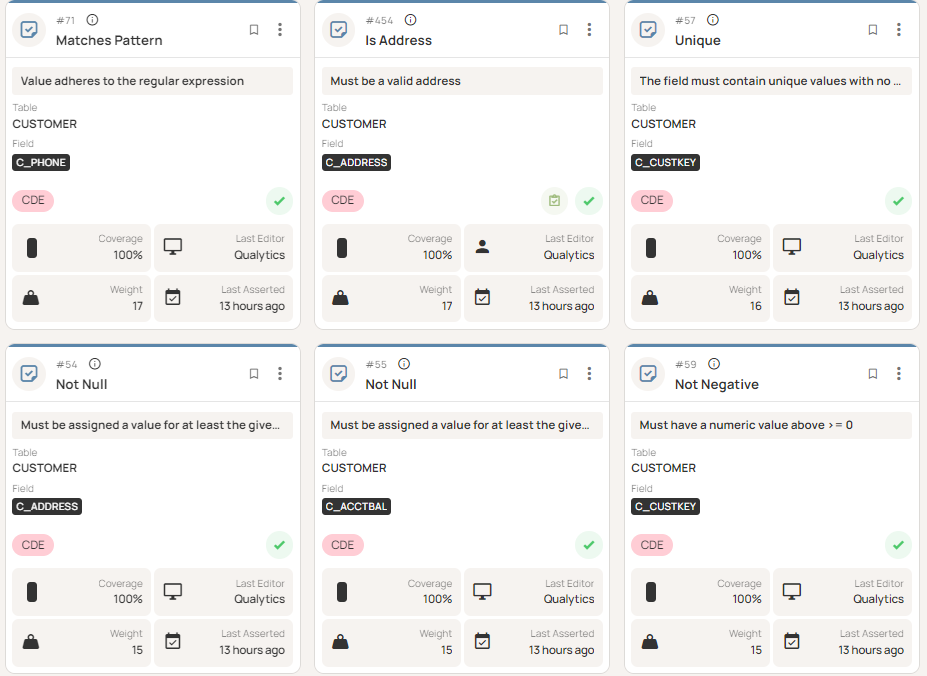
Automation can also assist by generating initial rules based on profiling results, reducing manual effort. Maintaining an audit trail ensures teams can track how rules evolve over time. As a best practice, these rules should be managed through a centralized interface, where teams can review, monitor, and update validation checks across datasets, as shown below.
Catalog-Profile-Scan execution model
Most data quality frameworks validate datasets using a three-stage workflow. This approach aligns with established data management practices such as those defined by the Data Management Association (DAMA). The workflow typically consists of the following stages:

In practice, this workflow operates as a continuous monitoring process. Datasets are regularly profiled and scanned so issues can be detected as soon as they appear, rather than waiting for periodic checks:
- Cataloging registers datasets and captures structural metadata such as schema, ownership, and location. This step provides visibility into what data exists across the platform.
- Profiling analyzes statistical characteristics such as distributions, null rates, and uniqueness. These insights establish a baseline for expected data behavior.
- Scanning applies validation rules to detect anomalies or rule violations. This is where issues are surfaced and made visible to the team.
Together, these stages form a repeatable workflow that continuously evaluates dataset health.
Scan scheduling depends on how pipelines operate. Batch pipelines often rely on daily scans, while event-triggered scans run after data loads, schema changes, or transformation jobs. Streaming pipelines may require near-continuous or micro-batch validation to detect issues in near real time.
As an example, consider a sales dataset used for reporting that is refreshed daily. During profiling, the system establishes that the order_amount field typically contains no null values. After a pipeline change, null values begin to appear.
During the next scan:
- A completeness rule detects the increase in null values.
- The anomaly is flagged for investigation.
- The issue is traced to a transformation step that failed to populate the field.
Once the issue is fixed, the anomaly is resolved. Over time, how similar issues are handled can improve detection and reduce unnecessary alerts.
Anomaly lifecycle
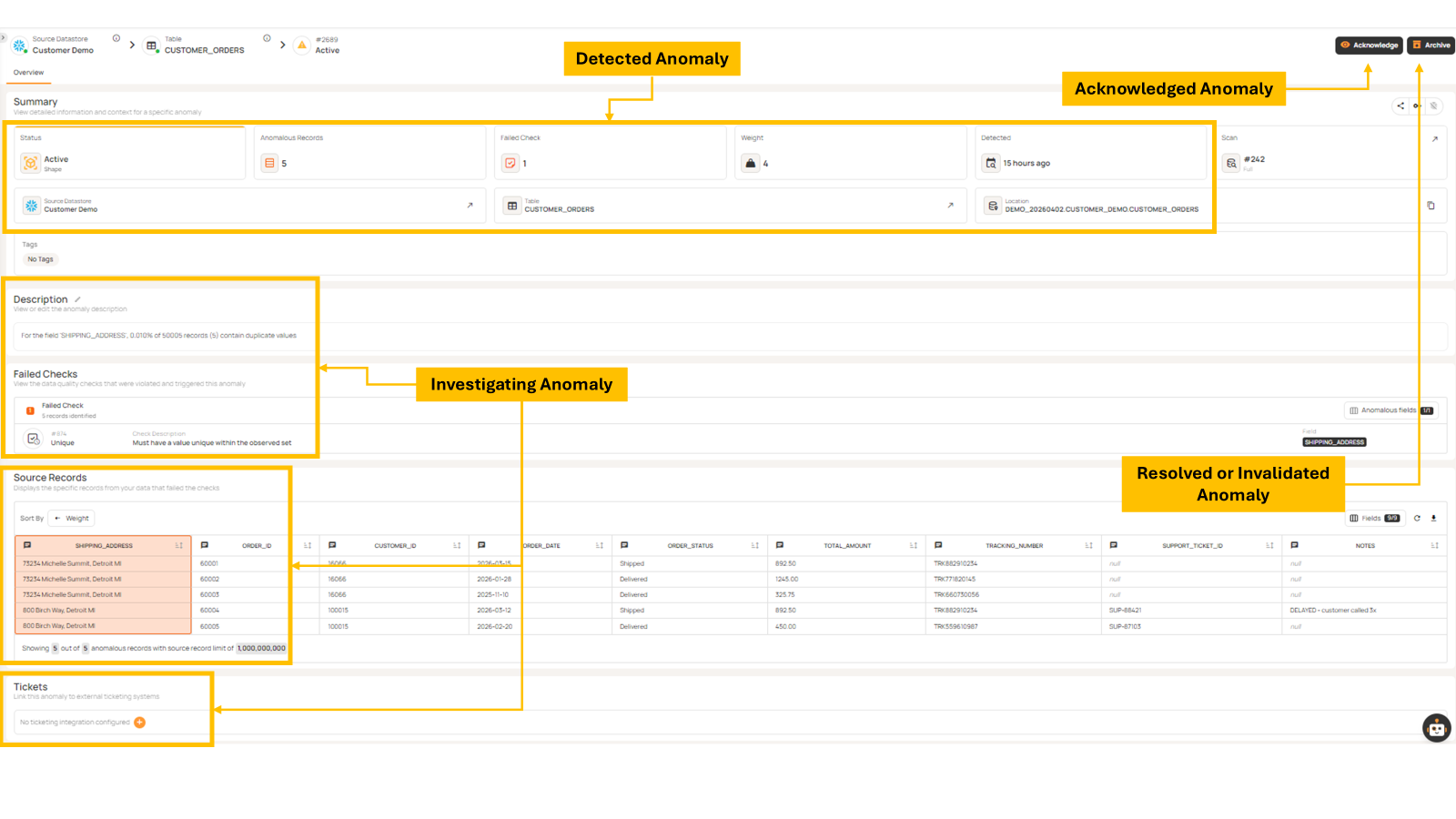
When a validation scan detects an issue, the anomaly follows a structured lifecycle, as shown below.
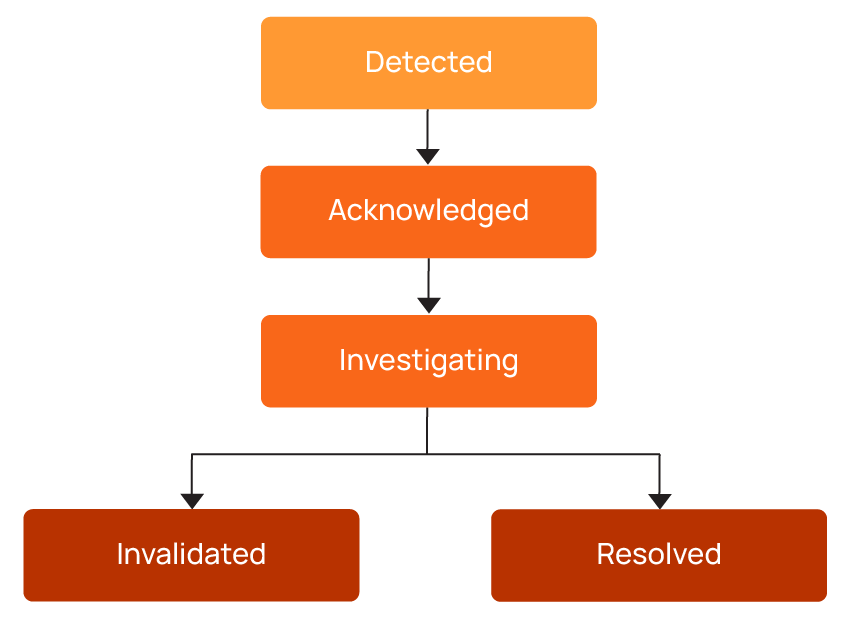
Each anomaly should have a clearly assigned owner responsible for investigating and resolving it. Without ownership, issues can remain unresolved or quietly bounce between teams without anyone taking responsibility.
Some anomalies may be invalidated if they are not considered true issues. How teams handle these cases—such as acknowledging anomalies, marking them as invalid, or adjusting validation rules—can help improve future detection and reduce false positives over time.
In many environments, anomaly handling is integrated with operational tools such as Jira, ServiceNow, Slack, or Microsoft Teams. Modern platforms like Qualytics also enable workflow automation to handle anomaly response systematically. This allows data quality issues to be addressed within existing workflows. Within the platform, anomalies are surfaced through a centralized interface where teams can review, prioritize, and investigate issues as they are detected. This provides visibility into how anomalies move through different stages of the lifecycle from detection to investigation and resolution, as illustrated in the lifecycle above.
The example below shows how these lifecycle stages are reflected in the platform interface. Anomalies are first surfaced with key context such as status, affected records, and metadata, allowing teams to quickly understand the scope of the issue. From there, teams can review failed validation checks and inspect the underlying records to investigate root causes. Based on this analysis, anomalies can then be progressed through the lifecycle by either resolving the issue or marking it as invalid.
Governance integration
Data quality processes are closely tied to governance and often involve ownership, policy enforcement, and accountability. For a more detailed discussion of how data governance and quality work together, see the data governance and quality article.
Assigning data owners and stewards to datasets ensures that responsibility is clearly defined. This helps reduce ambiguity and speeds up issue resolution.
Quality scores can be used to track whether datasets meet expected standards over time. Maintaining a record of quality findings allows teams to identify recurring issues and monitor trends.
Governance also defines escalation paths. Some issues may require broader attention, especially if they impact critical systems or compliance requirements.
{{banner-small-1="/banners"}}
Last thoughts
A data quality framework is built on six core components: a quality dimensions taxonomy, scope definition, rule management, a catalog-profile-scan execution model, an anomaly lifecycle, and governance integration. It helps teams move away from reactive fixes and toward a more structured approach. Instead of discovering issues late in dashboards or reports, teams can detect and resolve problems earlier in the pipeline through continuous monitoring and well-defined validation workflows.
Each component plays a role in making this work. Taxonomy and scope define what should be monitored, rule management and execution workflows define how validation is applied, and anomaly lifecycle and governance processes ensure issues are investigated and resolved in a consistent way.
In practice, implementing this end-to-end can become difficult as data environments grow. Platforms like Qualytics bring these components together by combining automated rule generation, continuous monitoring, and anomaly management into a coordinated environment. Qualytics allows teams to spend less time maintaining validation logic and more time understanding and resolving data quality issues.
Chapters
Improving Data Governance and Quality: Better Analytics and Decision-Making
Learn about the relationship between data governance and quality, including key concepts, implementation examples, and best practices for improving data integrity and decision-making.
Data Quality Checks: Tutorial & Automation Best Practices
Learn the fundamentals of data quality checks, like structural and logical validation, monitoring data volume, and anomaly detection, using practical examples.
Data Quality Assessment: Tutorial & Implementation Best Practices
Learn systematic approaches to assess data quality using automated tools and best practices for reliable validation.
Data Quality Dimensions: A Complete Guide with Examples
Learn the eight data quality dimensions every data engineer needs to ensure reliable, accurate data pipelines.
Data Quality Scorecard: Dimensions, Granularity, and Best Practices
Learn how a data quality scorecard helps you measure, track, and improve your organization's data quality.
What to Look for in Data Quality Software: A Guide to Features
Learn which data quality software features help teams build and sustain scalable, automated quality programs.
From Reactive to Reliable: A Guide to Modern Data Quality Frameworks
Learn the six core components of a data quality framework and how they work together to ensure reliable data.
Data Quality Automation: How Modern Platforms Validate at Scale
Learn how automated data quality platforms infer validation rules, detect anomalies, and support remediation at scale.
Data Validation Software: 10 Must-Have Features to Look For
Learn how to evaluate data validation software using 10 must-have features for scalable, automated data quality.
The Data Quality Maturity Model: A Six-level Model for AI Readiness
Learn the six-level data quality maturity model that maps your organization's path from ad hoc fixes to proactive AI-augmented governance.
Data Quality Metrics Examples: The Complete Guide
Learn how to turn abstract data quality dimensions into computable, actionable metrics that catch pipeline failures and data errors before they become incidents.
How to Choose the Best Data Quality Tools for Your Team: Key Features and Benefits
Learn what modern data quality tools do, why they matter, and how they use AI and automation to keep your data trustworthy.