AI removes the human safety net that contained bad data. The data control layer validates data at the moment it's acted on.

May 19, 2026
7
min read
Table of Contents

Bad data has always caused damage, and most of it was never caught. A financial analyst built a revenue forecast on customer acquisition cost data entered with the wrong decimal point. A procurement team renewed a vendor contract based on utilization figures that stopped refreshing six months ago after a pipeline change. No alert fired or ticket was opened. The decision just got made.
These weren't edge cases - just a typical Tuesday. The reason the damage stayed somewhat manageable wasn't that quality tools caught the problems. It's that a human was always at the end of the chain, making one decision at a time, at human speed. The blast radius of any single bad data point was naturally limited by how slowly people work and how few systems one person touches.
AI removes that limiter. Copilots and agents don't have the contextual judgment to question whether the data they’re acting on is trustworthy. A human analyst might look at a number and think “that doesn’t seem right” before putting it in a forecast. AI systems don’t have that instinct: they retrieve context, reason on it, and execute continuously across every connected system, propagating what they find in a nondeterministic manner. Where a single analyst reviews a number and makes one decision, an agent reconciling transactions, updating records, and triggering workflows can propagate a single bad data point into hundreds of downstream operations before any human sees an output.
Matt Robuck, VP of Data & Analytics at Georgia-Pacific, shared a version of this in a recent Qualytics webinar. His team deployed an AI agent on a sales dataset to help reps win deals faster. The agent was in production within two weeks, but it took the team another six months before those answers were actually trustworthy and useful.
The cost of bad data has always been significant. What changed is that the accidental safety net of human scale is gone. AI operates without the contextual awareness that let humans absorb bad data quietly for decades.
The architecture required to address this is a data control layer, where data quality operates as a system of signals applied at the point of use. To understand why that model is necessary, it helps to understand what the tools most enterprises rely on were actually built for.
What legacy tools were actually built for
The Data Quality Maturity Model maps six levels of data quality practice, from ad hoc incident response to AI-augmented control. Levels 0 through 3 describe the approaches most enterprises still rely on today.
At the earliest levels, there's no formal practice at all. Issues surface only after someone in the business notices something wrong, and fixes are applied one at a time until the same problem reappears. As organizations mature, they embed validations into SQL and Python, accumulating checks across repositories. Eventually, they centralize those rules in a dedicated platform. Coverage becomes more visible and governance more structured, but every rule still requires a human to author, maintain, and update as data models and business definitions evolve. Coverage can only expand as fast as specialized teams can sustain it. The underlying assumption stays the same: find what broke, fix it, write a rule to catch it next time.
Data observability tools emerged as a response to these scale limitations. They improved pipeline reliability meaningfully for data engineering teams, answering questions about whether the right volume of data arrived at the right time and whether pipelines ran correctly. But observability doesn’t evaluate whether a value is correct, whether a KPI is calculated according to business policy, or whether a dataset is fit for the decision it's about to drive.
Neither traditional data quality nor observability was built for the moment data is acted upon. Most organizations feel that gap every day. They just don’t have tooling that addresses it.
.avif)
AI raised the stakes and exposed the architecture
Every approach described above covered known failure modes. AI exposes everything else. The rules were always a step behind, written to catch the last failure rather than anticipate the next one. That was a manageable limitation when humans were absorbing the uncovered risk at human speed. Once AI starts acting on that same data continuously and autonomously, the uncovered risk stopped being a gap teams could work around and became a liability that compounds with every agent execution. And AI doesn't just consume the data humans were already using. It pulls in fields and tables that were never part of any quality program because no human ever made a decision on them. An agent deriving correlations across data points that no one anticipated using together is operating entirely outside the boundaries of whatever rules exist.
The instinct is to respond with more automation: AI that detects anomalies without the manual overhead. It sounds like the right move at first, but detection at scale without governance at scale makes the problem worse, not better.
AI-only tools take the wrong approach
AI-only anomaly detection may spot that something changed without knowing whether that change violates a business rule, because no one ever defined the business rule anywhere the system can find it. If an anomaly is detected, there's no auditable rule behind it, no defined owner responsible for it, and no resolution context for acting on it.
There's a more fundamental issue. Governance requires explicit policy that defines acceptable behavior, clear ownership that assigns accountability, and human judgment about what "good" means in a specific business context. When an AI system is deciding whether data is trustworthy enough for another AI system to act on, that judgment needs human-defined policy behind it. Without it, there's no audit trail connecting a decision to the business logic it should have been evaluated against.
Fully autonomous data quality tools remove humans from the loop when governance matters most. The answer isn't less AI. It's AI that operates within a governed framework where humans define the standards and the system scales them.
Data control is how quality finally scales
Every level of the maturity model addressed a real limitation of the one before it. Centralized governance replaced scattered code-level checks. Automated monitoring replaced manual pipeline inspection. But across every level, validation still happened after the fact, at predefined checkpoints, not at the moment data was used. AI-only tools, for all their detection power, left governance as an afterthought.
The question every prior approach left unanswered is the same one AI makes urgent: how do you know the data is trustworthy at the exact moment it's acted on?
A quality score attached to a dataset at pipeline ingestion doesn't answer that question for a copilot retrieving context six hours later, or an agent executing a workflow against data that has since changed. The answer has to be in the signal itself, delivered at the moment a decision is made. That's what we call validate-at-use: data quality evaluated at the point of consumption, not at a predetermined checkpoint upstream.
That premise is the foundation of the data control layer. It brings together AI-augmented quality coverage that scales without manual effort, a shared foundation where business teams, data teams, and AI systems govern data together, and trusted signals delivered as controls at the point of use. Quality signals, including AI-inferred rules, human-defined policies, anomaly history, and resolution context, travel with the data wherever it's consumed. A sales dashboard reflects the current state of the underlying data, not the state from the last scheduled scan. A copilot retrieving context for a quarterly review receives an anomaly flag before generating its output. An agent preparing to execute an ad spend change is blocked when the source data fails a quality check. These signals reach every consumer through the same governed foundation: business teams and data teams through Qualytics' purpose-built platform, external copilots through MCP, and autonomous agents through the API.

What makes this scalable rather than just another governance burden is the feedback loop. Governance has always required someone to decide that a dataset needed a rule, author that rule, and maintain it over time. Every new data asset, schema change, or upstream system update created new manual work. The data control layer changes that dynamic. AI infers and maintains 95%+ of rules automatically, recalibrating as data changes. And every time a team member reviews an anomaly, resolves an exception, or refines a rule definition, that decision feeds back into the system, making the rules smarter and the coverage stronger over time. You build a system where human judgment compounds rather than resets, and the context that humans use to understand and trust their data is the same governed foundation that copilots and agents operate on.
The foundation your AI depends on
Data quality maturity comes down to one thing: whether trust scales alongside innovation. The alert fatigue, coverage gaps, and recurring investigations into mismatched numbers that most teams live with today are not process failures. They’re the predictable outcomes of an architecture that was designed for a different era. Every organization building AI into production workflows will hit this ceiling. The question is whether you recognize it as an architecture problem or keep trying to solve it with the wrong tools.
The organizations that get this right are making a deliberate decision now: establish validate-at-use as the standard, treat the data control layer as the foundation, and build AI initiatives on governed context rather than hope. Act on trusted data, every time. Control the context powering your analytics, your AI, and your operations.
Chapters
Related Articles
Qualytics Introduces the Data Control Layer for Trusted Context
AI systems depend on context, but context without control creates risk. Qualytics introduces the data control layer that enables trusted data at the moment it is used.

From Firefighting to Foresight: Building Trust Through Augmented Data Quality
Move from reactive cleanup to proactive trust. Here’s how augmented data quality empowers Chief Data Officers with trusted, AI-ready enterprise data.
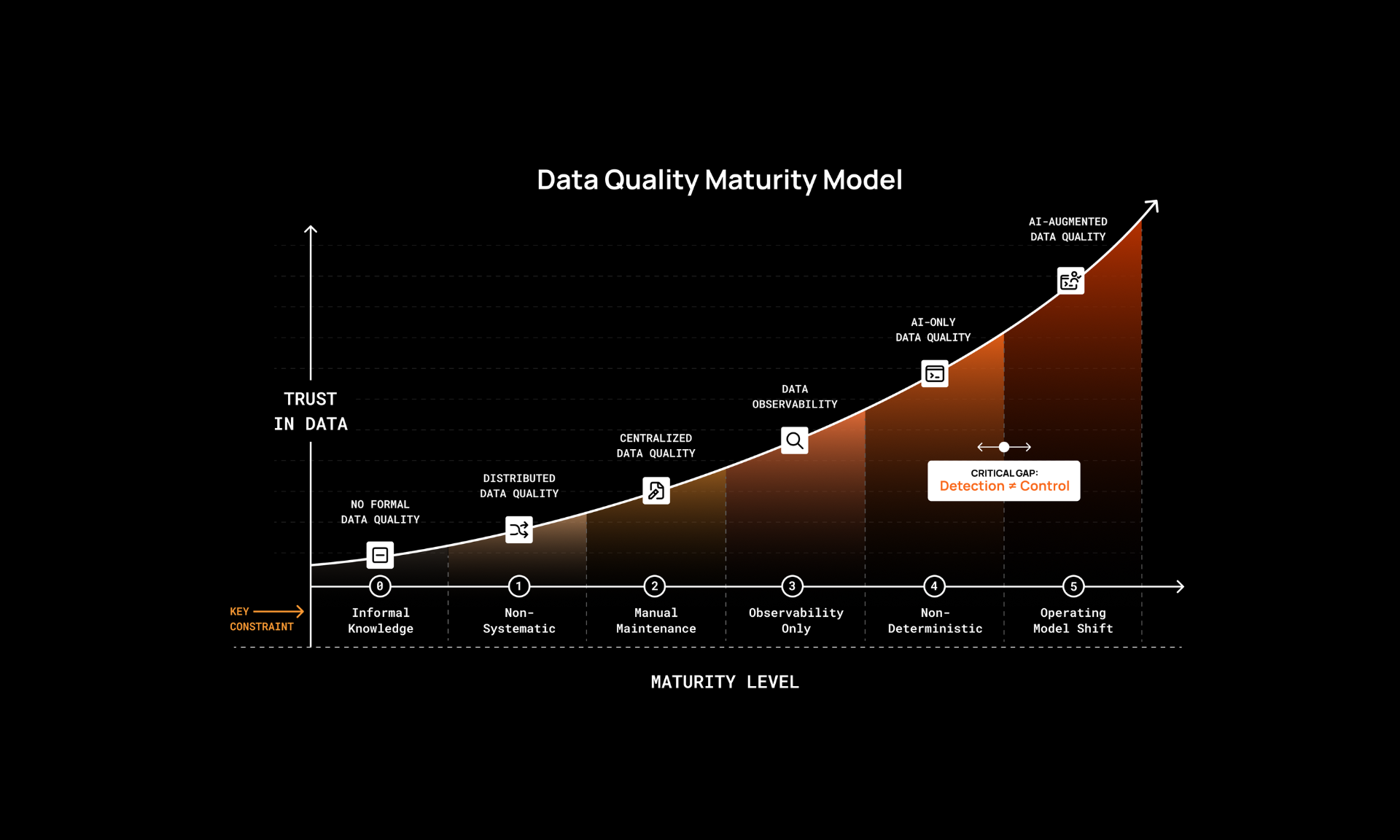
The Data Quality Maturity Model: Moving from Incident Response to Proactive Data Trust
A framework outlining how organizations evolve data quality into proactive, governed control across complex data environments.
Related News
Qualytics Introduces the Data Control Layer for Trusted Context
AI systems depend on context, but context without control creates risk. Qualytics introduces the data control layer that enables trusted data at the moment it is used.
From Firefighting to Foresight: Building Trust Through Augmented Data Quality
Move from reactive cleanup to proactive trust. Here’s how augmented data quality empowers Chief Data Officers with trusted, AI-ready enterprise data.
The Data Quality Maturity Model: Moving from Incident Response to Proactive Data Trust
A framework outlining how organizations evolve data quality into proactive, governed control across complex data environments.
