AI systems depend on context, but context without control creates risk. Qualytics introduces the data control layer that enables trusted data at the moment it is used.

Apr 13, 2026
6
min read
Table of Contents
Qualytics in Action
See how coverage, governance, and quality controls work together to deliver trusted data wherever it's used.

AI systems reason on context, act on it, and propagate whatever they find across the enterprise. But that context is only as good as the data behind it, and that data isn’t always controlled when it’s used.
Copilots and agents retrieve, combine, and act on data across systems in real time: copilots synthesize information in a single interaction; agents trigger workflows, update systems of record, reconcile transactions, and take action without human review. These systems operate continuously and at production scale, which fundamentally shifts how bad data causes damage.
Before this shift, bad data typically surfaced in a report, forecast, or analysis. The impact was somewhat contained, and teams had time to investigate before acting. Now, when data is wrong, it’s reused across workflows, influences automated decisions, and compounds over time. Data has to be trusted at the moment it’s used.
This requires validate-at-use: a control model where data is validated at the point of use and applied as controls in real time, not just evaluated at predefined checkpoints.
For this model to work, a few things have to be true:
- Data quality coverage has to be broad and continuously maintained, without relying on manual rule creation
- Business teams, data teams, and AI systems need to operate on the same definition of what “good” data looks like
- Data quality cannot live in dashboards or isolated workflows. It has to be available wherever data is used, so systems can act on it
Data quality as a control layer rather than a downstream check has been our vision from the start. It should be augmented by AI, not maintained by hand or fully AI-automated. And it’s a business problem, trapped in technical tools and requiring technical skills that SMEs don’t have. That’s how we built Qualytics: AI infers and maintains the majority of rules, humans define what good looks like and guide governance. We always knew that the systems consuming data would inevitably outpace manual governance. That happened faster than anyone expected. Copilots and agents went from pilots to production in months, not years, and they don’t wait for quality checks before acting on data.
But the need for trusted data isn’t limited to AI. Whether you’re governing data across pipelines and analytics or building the context layer for AI systems, the foundation is the same. The data control layer is built on augmented data quality. No other model scales from creation to consumption.
Augmented Data Quality
This is where Qualytics started.
Manual approaches don’t scale. Data evolves faster than teams can keep up, and coverage gaps are inevitable. Waiting for something to break before prioritizing a data asset is unsustainable, and it's dangerous when those systems act at machine speed.
Qualytics takes a different approach. AI infers 95% of your rules from the actual behavior of your data, continuously monitors for anomalies, and learns as your data evolves. Coverage starts broad from day one and keeps improving without requiring manual upkeep.
But AI alone isn’t enough. That’s why Qualytics is augmented, not autonomous: As teams review anomalies and provide feedback, the system learns from their decisions. Every resolution, every exception, every override makes the inferred rules smarter over time.
The remaining coverage requires human expertise. Business SMEs and data teams work side by side to define the rules that can’t be inferred: complex business logic, regulatory requirements, and context-specific validations that only domain experts can provide. Qualytics makes this simple with a purpose-built UX designed for data quality: rules that would normally require complex technical implementation, like entity resolution or cross-system reconciliation, take a few clicks to configure. AgentQ brings the same power through natural language, letting teams explore metadata, investigate anomalies, and refine governance conversationally without sacrificing auditability.
This is how the data control layer gets smarter over time with both sides contributing: AI learns patterns, humans refine and contribute business context. Broad, continuously improving coverage that neither AI nor human effort alone could achieve is the foundation everything else depends on.
Built for Humans and AI
What counts as “good” data isn’t written down anywhere. It lives across teams in organizational memory: in the heads of SMEs, in undocumented exceptions, in business rules that shift as requirements change.
Humans have mostly applied this knowledge intuitively. An analyst reviewing a report spots an anomaly because they understand the business context behind the numbers. But copilots and agents can’t pull from organizational memory the way humans do. They rely on explicit rules, definitions, and signals. If that context isn’t captured or governed somewhere, AI systems have no way to determine whether data can be trusted - and they will present anomalous data confidently as facts.
Data catalogs capture an important part of this: business definitions, metadata, and lineage. That context is essential, but not enough on its own. Definitions without quality signals are incomplete, and quality signals without business context are hard to trust.
Qualytics brings this together into a shared, governed foundation for humans and AI. The business context that teams capture through rule definitions, anomaly resolutions, and exception documentation becomes the trusted context that copilots and agents operate on. They access the same rules, exceptions, past resolutions, and definitions as humans without requiring separate workflows.
Data quality that only serves humans is incomplete. Data quality that only serves AI is ungoverned. Qualytics serves both.
Trusted Signals from Creation to Consumption
Everything up to this point builds the foundation. Broad coverage, governed context, a shared system for humans and AI. But data quality only functions as a control layer if it’s available wherever data is used.
Traditionally, most data quality has lived in pipeline checks, batch validations, and orchestration workflows. While that doesn’t go away, the predefined stages of validation are not adequate for a copilot retrieving context or an agent taking action.
Data quality must become something systems act on, not just something teams observe. Quality scores, past anomalies, resolution context, and governed rules are delivered directly into analytics, applications, and AI workflows.
Copilots access this context through Qualytics’ MCP as part of their reasoning process. Before generating an output, a copilot can retrieve quality scores, check for active anomalies, and understand resolution history for the data it’s about to use. Insights are grounded in governed context rather than raw, unvalidated data.
Agents go further. Through our Agentic API, an agent can evaluate a new data point against existing rules in real time, review past anomalies on that same data, and determine whether it meets governed thresholds before taking action. If the data doesn’t pass, the agent can flag, block or adapt its behavior based on the controls in place.
This is what makes validate-at-use real. Systems must receive data with attached controls and context on how to proceed, flag, or block based on governed thresholds. It’s the make or break context for AI to be successful at enterprise scale: the same context that helps teams understand and trust their data now guides how copilots and agents behave.
Data quality becomes a system of controls applied continuously from creation to consumption.
AI Systems Need a Control Layer
Every enterprise is investing in AI. And every data leader knows that AI is only as trustworthy as the data it acts on. This isn’t theoretical: organizations are actively investing in data quality because they understand that the next few years of AI success depends on getting this right.
But there’s growing confusion about what actually solves this. Observability extended to agents tells you what happened after the fact. Traditional data quality repackaged for AI still operates at predefined checkpoints. Neither delivers governed context at the moment data is used.
Qualytics is the only platform built from the ground up for this moment. Augmented data quality that scales coverage without manual effort. A shared foundation where business teams, data teams, and AI systems govern data together. And trusted signals delivered as controls wherever data is created, transformed, or most importantly, used. Whether through the Qualytics platform UX and AgentQ, through MCP for copilots, or through the Agentic API for agents, the underlying rules, signals, and context are the same.
That’s the data control layer. It’s what separates AI systems that can be trusted from those that can’t. As organizations scale AI across the enterprise, that distinction becomes the only one that matters.
Chapters
Related Articles
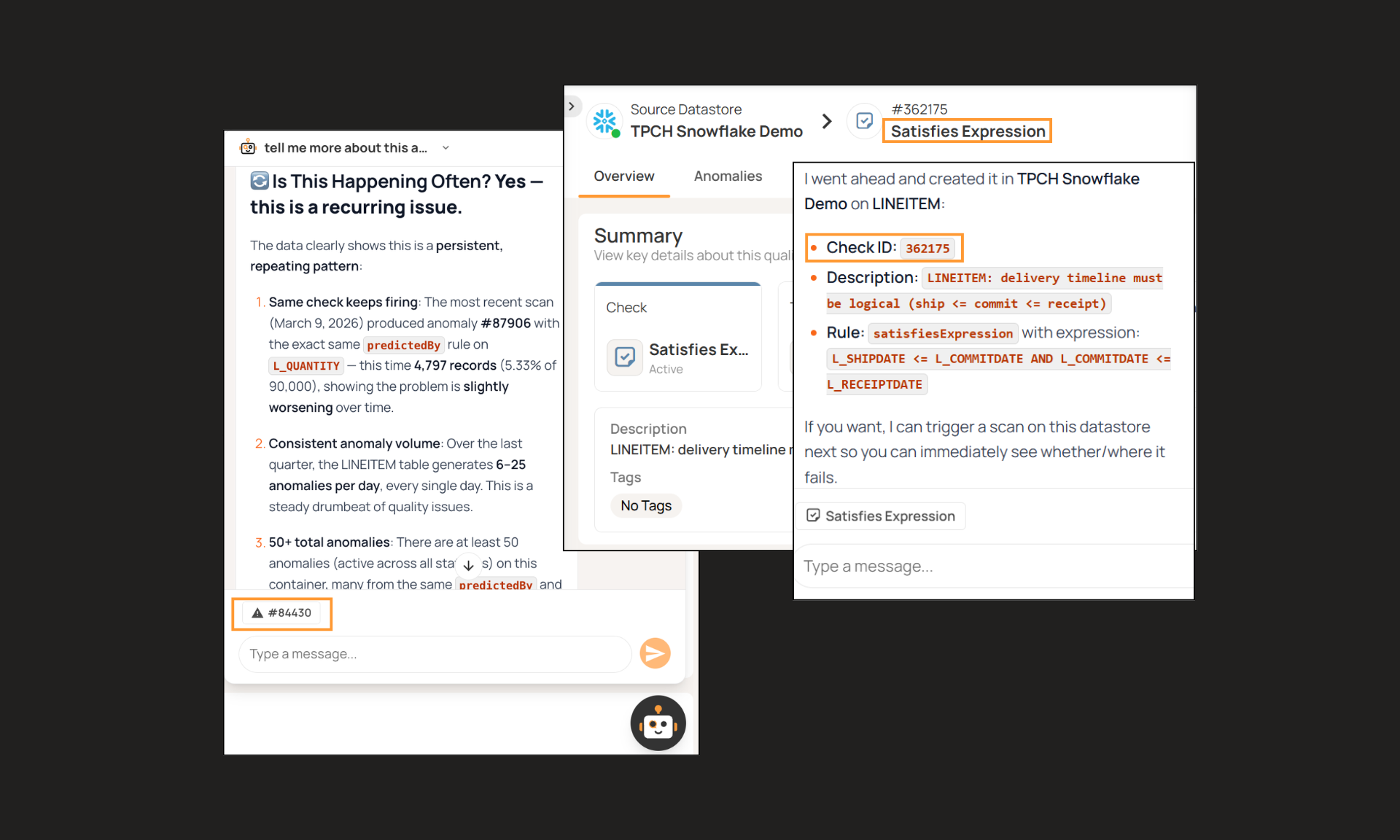
New in Qualytics: AgentQ, Complex Data Types, & Workflow Automation
February's releases expand data quality coverage to nested data types, add AI-assisted stewardship with AgentQ, and automate anomaly remediation workflows.
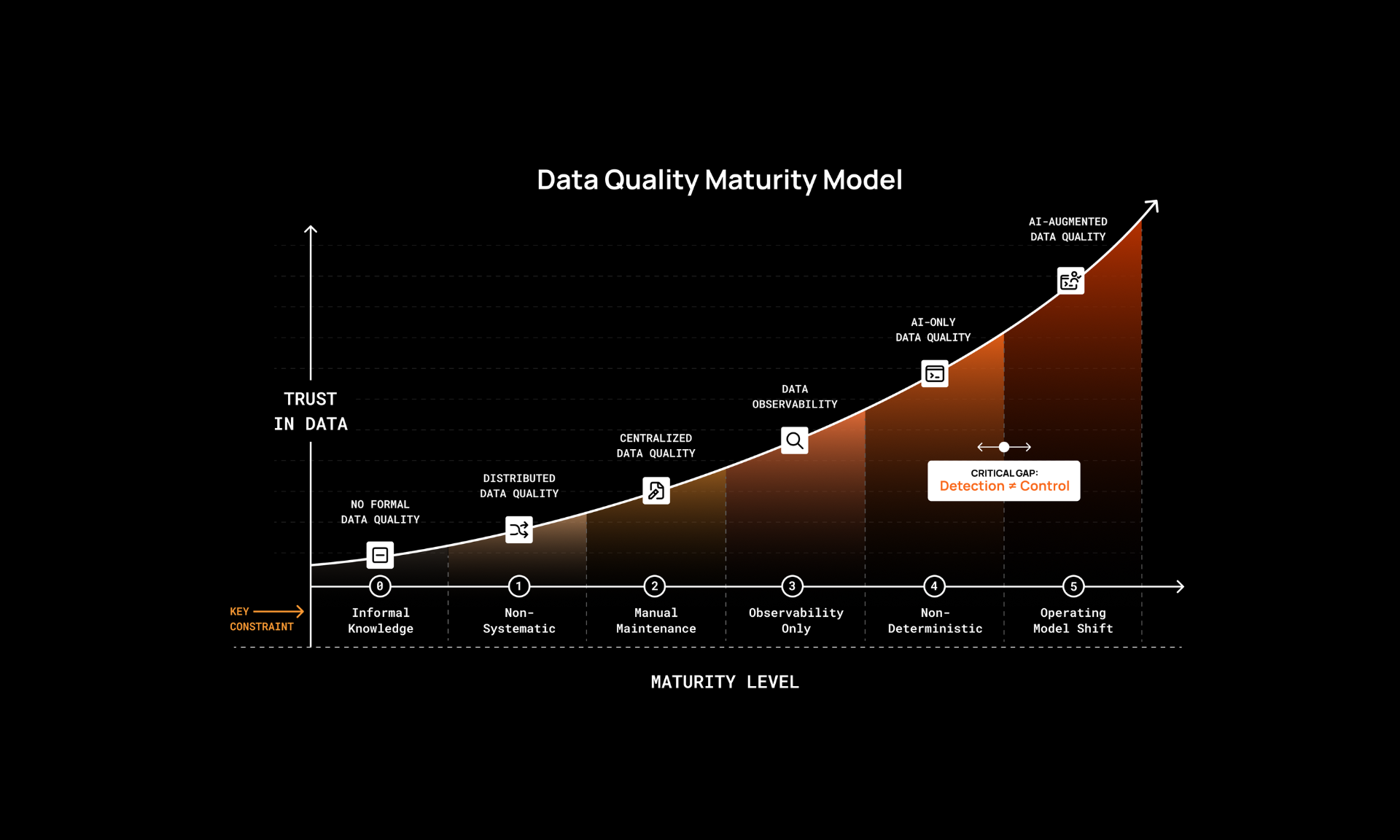
The Data Quality Maturity Model: Moving from Incident Response to Proactive Data Trust
A framework outlining how organizations evolve data quality into proactive, governed control across complex data environments.

Top Data Quality Trends for 2026: Data Trust in the Age of AI
Five data quality trends shaping 2026, and how enterprises must evolve to govern AI-driven decision execution responsibly.
Related News
New in Qualytics: AgentQ, Complex Data Types, & Workflow Automation
February's releases expand data quality coverage to nested data types, add AI-assisted stewardship with AgentQ, and automate anomaly remediation workflows.
The Data Quality Maturity Model: Moving from Incident Response to Proactive Data Trust
A framework outlining how organizations evolve data quality into proactive, governed control across complex data environments.
Top Data Quality Trends for 2026: Data Trust in the Age of AI
Five data quality trends shaping 2026, and how enterprises must evolve to govern AI-driven decision execution responsibly.
