AI-augmented data quality on Databricks, delivering proactive profiling, scalable rules, continuous monitoring, and governed remediation for trusted analytics and AI.

Mar 3, 2026
6
min read
Table of Contents
See how Databricks + Qualytics work together
to deliver trusted analytics and AI at lakehouse scale with profiling, rule coverage, continuous monitoring, and governed remediation running natively on the lakehouse.

Enterprises turn to Databricks to power analytics, machine learning, and AI at scale on a unified lakehouse architecture. By bringing data engineering, BI, and AI workloads together, Databricks helps teams move faster from ingestion to insight to action while operating on a single, governed foundation.
As organizations scale AI and analytics on Databricks, maintaining trustworthy data becomes exponentially harder. Data pipelines evolve, schemas drift, distributions change, and business logic gets revised. If those changes aren’t detected and addressed, dashboards, data products, models, and AI agents can produce unreliable outcomes. Reliability depends on continuously validating that data still behaves as expected, not only processing data efficiently.
Qualytics complements Databricks by providing an AI-augmented operational data quality layer that runs natively on the Databricks Data Intelligence Platform. Qualytics helps teams establish behavioral baselines, scale rule coverage, continuously monitor data across pipelines and medallion layers, and remediate issues with clear ownership and downstream impact context.
Together, Databricks and Qualytics support four operational data quality pillars for trusted data at scale. The pillars below outline how teams define “normal,” detect change early, validate downstream impact, and drive accountable remediation.
Pillar 1: Profiling and Behavioral Baselines Without Manual Sampling
As data grows in size and complexity, spot-checking is not an effective strategy. Enterprises often manage thousands of tables fed by hundreds of pipelines, and changes happen constantly. New fields appear, distributions drift, keys lose integrity, and null patterns shift. Without continuous visibility into how data behaves over time, teams end up operating on assumptions, and issues surface only after they have already impacted reporting, analytics, and AI systems.
Databricks makes it easy to ingest and store data. Qualytics continuously profiles that data to understand and track its structure and behavior over time.
Qualytics does this by continuously profiling tables, views, and files inside Databricks and establishing behavioral baselines that evolve with your data. Instead of relying on manual sampling, teams get continuously validated expectations for each field and dataset based on real production behavior.
Profiling capture signals such as:
- Structure and shape: observed types and formats, nullability patterns, schema drift indicators (added/removed columns, type changes)
- Cardinality and key behavior: uniqueness and duplication rates, primary key coverage, join-key stability signals
- Value distributions and drift: ranges, quantiles, outlier rates, categorical churn, distribution-shift markers
- Cross-field relationships: correlation and consistency signals that catch issues that look valid in isolation but break in combination
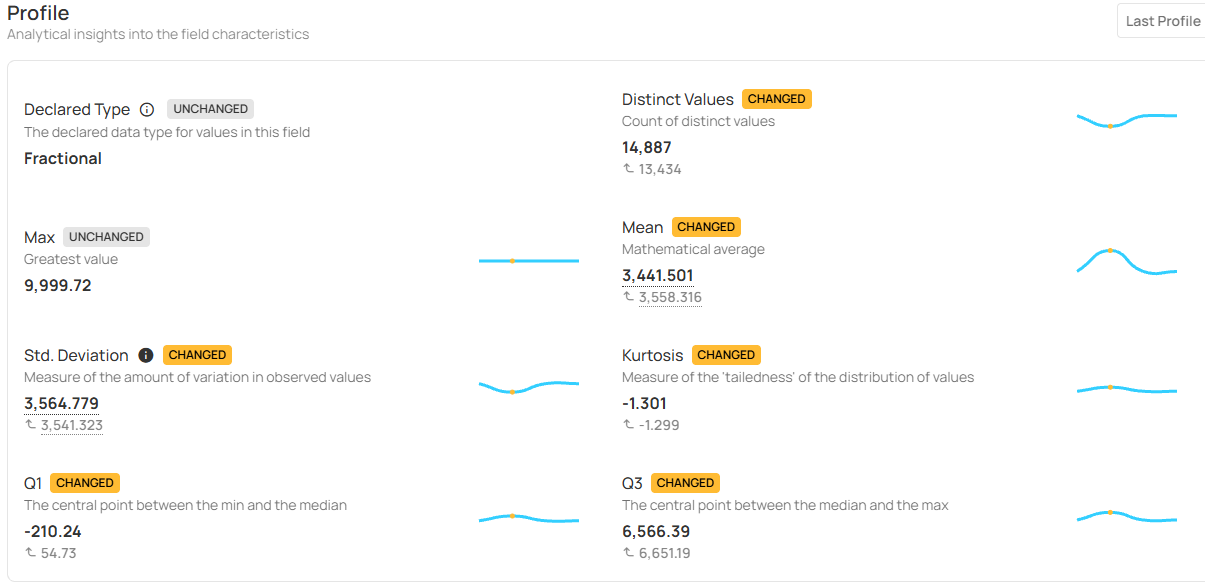
Baselines are learned from the data in your environment, making thresholds match real production behavior instead of generic assumptions. For segmented datasets, Group By profiling maintains separate baselines by tenant, region, market, or business segment without duplicating work. This helps teams catch issues that appear only within a specific slice of the data.
The outcome is a scalable way to learn and continuously refresh what “normal” looks like. This makes data quality changes visible early, rather than surprising teams later.
Pillar 2: Scalable Rule Coverage Without Scaling Headcount
Manual rule management cannot keep up with the speed and volume of data changes and new sources. High manual overhead pushes teams to write rules after incidents, which keeps coverage thin and thresholds stale as data changes. Without a centralized view of enforcement and coverage, teams recreate rules across tools, lose visibility into what is covered, and manage data quality reactively instead of systematically.
Databricks makes it easy to transform data. Qualytics provides a unified data quality layer to author, version, deploy, enforce, and monitor rules across the lakehouse.
Qualytics makes rule coverage scalable by shifting rule creation from a manual bottleneck to an automated, guided workflow that runs in Databricks:
- Auto-suggested technical rules: infer types, formats, null thresholds, uniqueness, allowed sets, referential checks from observed behavior
- Operational observability rules: generate freshness expectations, arrival cadence, volume bounds, and missing-partition checks to protect pipelines
- Behavior-aware thresholds: calibrate and update thresholds as “normal” shifts to reduce false positives and retuning
- Cross-field and model-based rules: enforce higher-order invariants across columns/tables (e.g., revenue ≈ orders × price), correlation checks, consistency constraints
- Guided business rule authoring: enable SMEs to extend logic through templates and low-code/no-code patterns, while engineers retain full-code control for edge cases
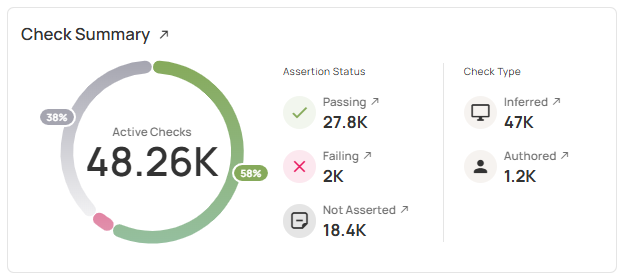
This approach also improves collaboration. Business owners can contribute directly to definitions, stewards can review exceptions and outcomes, and engineering teams can enforce standards with versioning, promotion/rollback, and dry-run validation against production data before deployment.
The outcome is rule coverage that grows with the lakehouse, without requiring additional headcount.
Pillar 3: Continuous Monitoring and Validation Across Pipelines and Medallion Layers
Data is continuously moved, combined, and transformed; detecting issues late in the pipeline is costly. Medallion architectures (bronze → silver → gold) process high volumes through many transformations and joins, where small regressions compound quickly. A join cardinality shift, silent schema drift, or gradual distribution change may not fail a job, but it can quietly distort KPIs, degrade ML features, and distort agent behavior before teams notice.
Databricks makes it easy to build and orchestrate pipelines. Qualytics continuously validates data as it moves through those pipelines, detecting issues closer to the source and earlier in the lifecycle.
Qualytics shifts monitoring from batch-only validation to continuous validation inside Databricks, applying rules and checks inside pipelines and at each medallion layer. Monitoring and validation cadence can match risk profiles, such as inline for critical pipelines, frequently for high-change sources, and less frequently for stable reference datasets.
Continuous validation captures signals such as:
- Pipeline integrity: row count reconciliation, join cardinality stability, duplication and loss checks across bronze/silver/gold
- Schema and logic drift: detection of silent column changes, type shifts, and transformation regressions that pipelines may not fail on
- Behavioral drift: distribution changes, null inflation, and outlier patterns that indicate upstream or logic changes
- Downstream consistency: metric rollup validation, KPI stability checks, and data-diff comparisons between layers
- ML and AI readiness: feature behavior monitoring to catch drift before it impacts training, inference, or agent decision-making
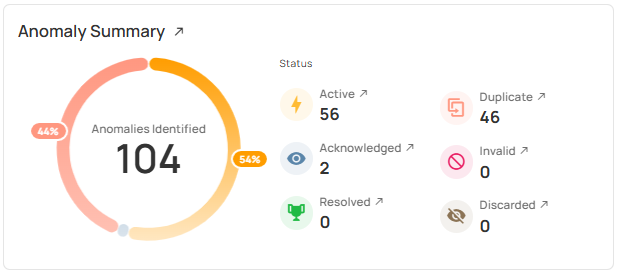
Monitoring is impact-aware by design. When a change is detected, Qualytics scopes impact from the specific field or table to the downstream datasets, features, dashboards, and workflows that depend on it. This makes validation actionable, not just observable.
The outcome is earlier detection, greater impact visibility, and fewer surprises downstream, making reliability a part of pipeline execution instead of handled through late-stage firefighting.
Pillar 4: Incident Response and Remediation Without Alert Chaos
Alerting does not equal operational data quality control. As monitoring coverage grows, teams are flooded with notifications, duplicated signals, unclear ownership, and little context about business impact. Engineers recreate investigations across tools, stewards chase false positives, and truly critical issues get lost in noise.
Databricks provides the execution environment. Qualytics provides an impact-aware incident layer that turns detections into prioritized, actionable events teams can resolve quickly and consistently.
Qualytics does this by correlating detections across rules, baselines, and pipelines and grouping them into governed incidents with clear context and ownership. Instead of dozens of alerts, teams see a small number of explainable incidents tied to real changes in data behavior.
Operational remediation includes:
- Noise reduction and grouping: deduplicate related alerts and group them by shared root causes or upstream changes
- Ownership and routing: assign incidents automatically based on dataset, domain, pipeline, or stewardship metadata
- Impact-aware prioritization: rank incidents by downstream risk to critical KPIs, data products, ML features, or agent workflows
- Actionable evidence: attach offending records, affected segments, historical context, and validation results for faster resolution and auditability
- Operational remediation: route incidents into existing tools (Jira, ServiceNow, Slack/Teams, on-call) and trigger gating and reprocessing actions via webhooks
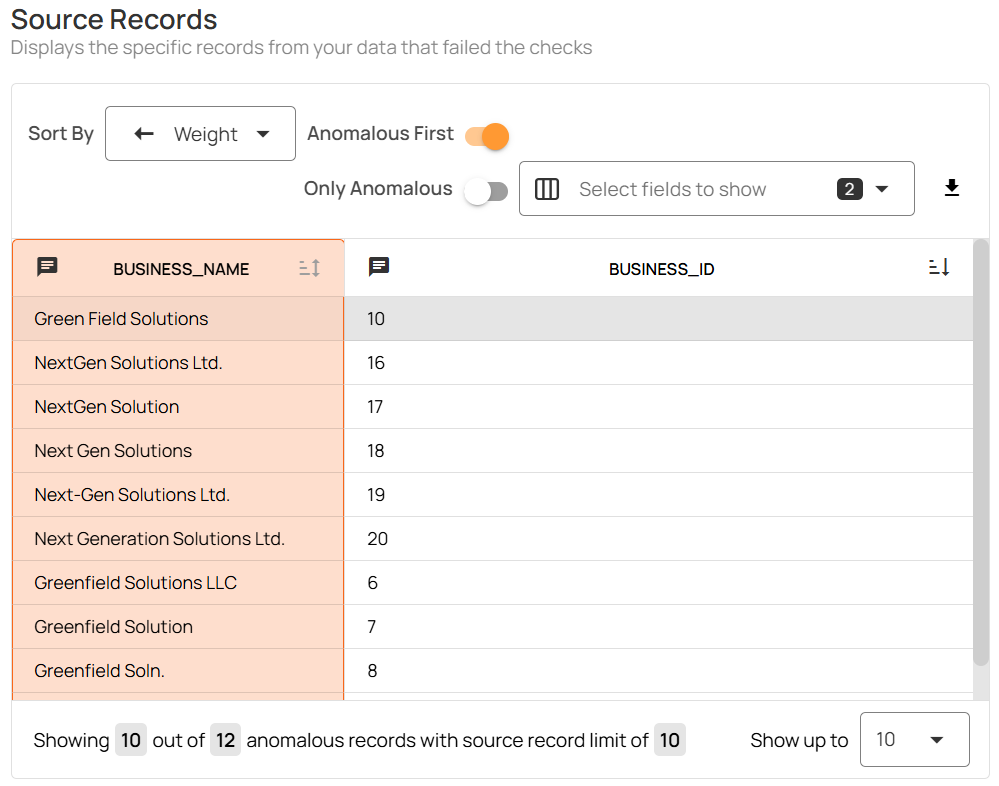
Because Qualytics is API-first, the same incident and remediation patterns can be embedded directly into orchestrators and CI/CD workflows, making response consistent across domains and teams.
The outcome is a governed, auditable incident lifecycle that scales with the lakehouse, enabling teams to spend less time managing alerts and more time fixing the issues that actually matter.
Runs Natively on the Databricks Data Intelligence Platform
A core advantage of this partnership is that Qualytics runs where the data lives, on the Databricks Data Intelligence Platform. It integrates with key platform services (including Delta Lake, Databricks SQL, Lakeflow Jobs, and Unity Catalog) so operational data quality becomes part of normal Databricks execution and governance.
Qualytics can run profiling, rule evaluation, monitoring, and anomaly scans as Lakeflow Jobs, scheduled alongside pipeline tasks with familiar dependencies, retries, and run monitoring. Because execution happens in-platform, teams can leverage Databricks elastic compute for scale while keeping sensitive data in the lakehouse and maintaining consistent governance through Unity Catalog permissions and auditing.
In practice, “native” matters because it reduces friction: quality is not bolted on after the fact; it becomes an operational layer embedded in Databricks workflows.
Better Together: Databricks + Qualytics
Databricks gives organizations the foundation to build analytics, ML, and AI at scale. Qualytics complements that foundation with an AI-augmented operational data quality layer that keeps trust aligned with data scale and velocity.
Together, the platform and the operational layer enable decision reliability through four capabilities that keep pace with change:
- Profiling and behavioral baselines that continuously define “normal”
- Scalable rule coverage that stays current as schemas and definitions evolve
- Continuous monitoring and validation across pipelines and medallion layers
- Impact-aware, governed remediation that turns detections into accountable action
If you’re building analytics, ML systems, or AI agents on Databricks, operational data quality is not a nice-to-have. It makes speed and scale sustainable.
Request a demo to see how Databricks + Qualytics work together to deliver trusted analytics and AI at lakehouse scale with profiling, rule coverage, continuous monitoring, and governed remediation running natively on the lakehouse.
Chapters
Related Articles

Qualytics Announces Technology Partnership With Databricks
Organizations can now run Qualytics natively on the Databricks Data Intelligence Platform, ensuring their data is accurate, explainable, and AI-ready without external processing.
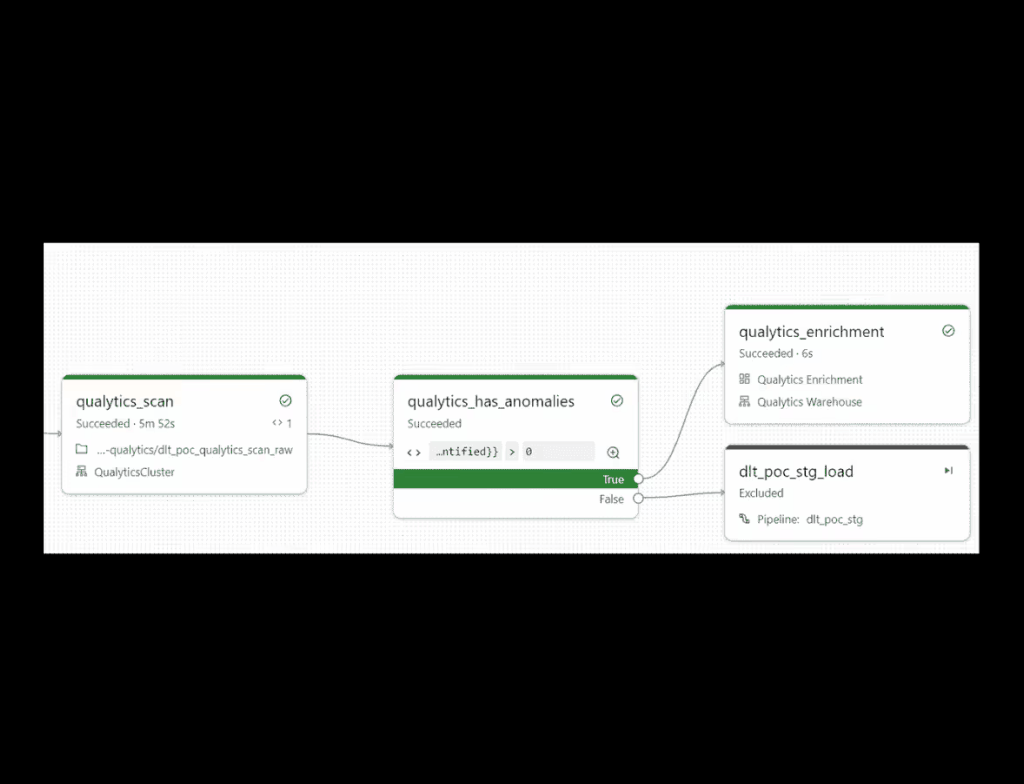
Databricks Workflow Integration
Technical overview of Qualytics and Databricks integration capabilities, featuring automated quality checks, monitoring workflows, and seamless lakehouse data validation features.

The Ultimate AI Readiness Playbook
Practical guide outlining seven essential steps for AI data readiness, covering quality assessment, cleansing strategies, governance frameworks, and validation processes.
Related News
Qualytics Announces Technology Partnership With Databricks
Organizations can now run Qualytics natively on the Databricks Data Intelligence Platform, ensuring their data is accurate, explainable, and AI-ready without external processing.
Databricks Workflow Integration
Technical overview of Qualytics and Databricks integration capabilities, featuring automated quality checks, monitoring workflows, and seamless lakehouse data validation features.
The Ultimate AI Readiness Playbook
Practical guide outlining seven essential steps for AI data readiness, covering quality assessment, cleansing strategies, governance frameworks, and validation processes.
