Manufacturers use Qualytics to validate part, supplier, and inventory data upstream before it reaches automated systems and AI.
Jun 16, 2026
9
min read
Table of Contents
See how manufacturers operationalize data quality across their most critical use cases.

In manufacturing, the same data feeds inventory decisions, procurement workflows, regulatory filings, and increasingly AI-driven systems, and when it is wrong every one of those inherits the error at once. Part and material master data, supplier feeds, production and quality records, and inventory positions flow through procurement, planning, maintenance, finance, regulatory reporting, and AI systems. When that data is unreliable, the impact shows up as carrying cost, expedited freight, idle production lines, audit findings, and stalled AI initiatives.
Controls keep operating on inconsistent, duplicated, or stale data long before anyone notices. Traditional data quality approaches surface issues downstream, on a dashboard, in a reconciliation, or during audit prep, late in the cycle. By then, automated processes and AI systems may have already turned small data defects into material business risk.
Manufacturers use Qualytics to enforce data quality upstream, validating data continuously before it reaches inventory decisions, procurement workflows, regulatory reporting, or AI systems. AI infers and maintains the rules while teams guide governance with business context, which moves the work from reactive cleanup to augmented data quality. These are the most common ways manufacturing organizations operationalize it.
Maintaining master data consistency across plants
In a multi-plant manufacturer, the same part, supplier, or material is often entered differently at every facility, frequently inherited from systems that came in through acquisition. The same motor appears under three descriptions. The same supplier is registered under two spellings. A spare part is classified as inventory at one plant and an expense at another.
These inconsistencies carry real cost. When one plant cannot see that a sister plant already holds the part, it reorders with expedited freight while the existing stock sits idle. Misaligned financial classifications distort spend reporting and erode supplier volume discounts, and they surface as audit findings that send teams back to reclassify and explain prior-period numbers.
Manufacturers use Qualytics to profile master data across every plant and surface the duplicates and mismatches that manual checks miss. Cross-field validation and entity resolution detect when the same part, supplier, or material is classified or described inconsistently across facilities. AgentQ lets data teams investigate these patterns in plain language and connect findings to business context.
In one engagement, a multi-plant manufacturer surfaced a 16% inconsistency rate in financial class codes across facilities within hours. Once the team attached dollar values by joining the parts master against procurement spend, the finding became the foundation of an inventory rationalization conversation worth hundreds of millions in working capital.
Reconciling inventory across multiple source systems
Manufacturing data lands in a single warehouse from 10 to 15 source systems at once, including ERP, MES, maintenance, procurement, and finance. Each system was built at a different time by a different team, with its own naming conventions and definitions. A basic question like "what is our actual inventory of a given part across all plants" returns a different answer from each system.
The breaks are familiar: the same physical part registered under different IDs across systems, parts shown as in stock that no one can locate, bills of material that no longer match what the line actually consumes, and shift counts that do not roll up cleanly to daily totals. No one is accountable for cross-source consistency, so the central data team gets blamed for numbers it did not create.
Manufacturers use Qualytics to profile every landing table and auto-infer rules per field, including expected cost ranges, quantity bounds, formats, completeness thresholds, and uniqueness. The platform detects the same item appearing under different IDs across systems and flags stale records automatically. Findings route to the team that owns each source system through integrations across the data stack, putting accountability where the fix lives instead of in a central triage queue.
Validating supplier and third-party data at ingestion
Manufacturers depend on data they do not control: vendor catalogs, supplier spec sheets, EDI transmissions, certificates of analysis, and logistics feeds. This data arrives with whatever quality standards the sender applied, and once it enters internal systems unchecked, the errors propagate into procurement, planning, and finance.
The failures show up in specific moments. An advance ship notice reports a quantity that does not match the purchase order. A material spec records the wrong alloy under the right part name. A regulated lot arrives without the certificate that allows it to be released to production. A supplier price file lands with a rate that does not match the contract, and the three-way match does not catch it before accounts payable pays.
Manufacturers use Qualytics to validate supplier data at the point of ingestion, before it spreads downstream. Coverage, completeness, freshness, schema, type, domain, and cross-field consistency checks run against external feeds as they land. The platform learns expected patterns from historical loads and flags the deliveries that do not fit, routing each issue to the team that has to follow up with the supplier.
One manufacturing prospect found 106 data quality issues tied to a single vendor. Supplier and distribution-center data is a consistent blind spot across enterprise supply chains, where partners rarely operate with the data discipline their customers depend on.
Reconciling data through ERP migration and consolidation
Manufacturers are migrating off legacy ERPs onto modern platforms like SAP S/4HANA, or consolidating systems after acquisitions, often against fixed vendor deadlines. The question at cutover is always the same: did the data make it across, and does it still mean what it used to mean? Master data loaded incorrectly at go-live poisons the new system from the day it turns on.
The risks are well known. Truncated descriptions leave buyers unable to identify parts. Duplicate vendor codes carry forward and multiply. Open purchase order lines transfer incompletely. Custom fields land in the wrong place or drop entirely. Unit-of-measure mismatches throw quantities off by a full case factor.
Manufacturers use Qualytics to run continuous reconciliation between legacy and target systems throughout the transition, rather than sampling manually at intervals. SAP S/4HANA connects directly, and legacy data is validated wherever the migration team stages it, typically a cloud warehouse or lakehouse maintained for parallel reporting during cutover. Automated profiling detects schema changes, drift, and format inconsistencies as they happen, so the team sees the picture in real time instead of assembling it at the eleventh hour.
Validating data before AI and agents act on it
Manufacturers are investing heavily in AI, including predictive maintenance, demand forecasting, supply chain agents, and yield optimization, with some running thousands of models in production. These systems act on data at machine speed without a human reviewing each decision. When the inputs are wrong, the error does not appear on a dashboard for review. It appears as an automated decision that already happened.
A predictive maintenance model pulls a healthy asset offline because a sensor read badly, and after a few false alarms the team stops trusting the system. A forecast updates on a partial load and shifts the production plan toward the wrong mix. An auto-replenishment routine orders stock the plant does not need. Each error scales as fast as the system that made it.
Manufacturers use Qualytics as the data control layer that validates data at the point of use, before AI systems consume it. Quality signals are delivered as real-time controls through MCP for copilots and the Qualytics API for agents, so a system can proceed, flag for a human, or block an action against governed thresholds. This is validate-at-use: data is evaluated before it drives a decision rather than checked after the fact. AgentQ operates as an expert agent that other agents can call when they need a data quality decision before acting.
At one manufacturer building agents on its own warehouse data, the first major finding came from AgentQ catching a 16% master-data inconsistency within six weeks of going into production, evidence that AI and data quality reinforce each other rather than compete.
Producing audit-ready evidence for regulatory reporting
Manufacturers operate under regulatory regimes that vary by what they make, including FDA electronic-records rules in pharma, FSMA in food, REACH and TSCA in chemicals, IATF 16949 in automotive, and SOX for anyone publicly traded. The audit question is consistent across all of them: show the controls that were active when the data was produced, the exceptions they caught, and what was done about each one.
The practical problem is that the evidence is scattered, living in engineering scripts, analyst screenshots, and spreadsheets that may no longer exist. Audit preparation becomes weeks of reconstruction, with the risk that the reconstructed trail has gaps an auditor will find.
Manufacturers use Qualytics to validate the data feeding regulatory controls with completeness, consistency, range, and aggregation-integrity checks, using rules that are versioned, explainable, and owned. This is where data governance and data quality meet: every check has a documented owner and every exception has a documented review and remediation. The audit trail is produced as a byproduct of normal data quality work rather than as a separate audit-prep project, so when a regulator asks for the controls active on a given batch on a given date, the answer is a query rather than a reconstruction.
One regulated enterprise relied on business and regulatory controls built on data that could change without detection. Qualytics generated 18,335 inferred rules automatically, saved roughly 2,950 engineering hours, and compressed a nine-to-twelve-month timeline to a single week.
Ensuring traceability and recall readiness
In regulated industries, manufacturers must trace every finished product back through every component, supplier lot, and process step. The data supporting that trace lives across procurement records, receiving logs, batch records, quality results, and shipping manifests, each in a different system with its own quality issues.
The fear in a recall is not the recall itself. It is not knowing the scope. When a potentially affected lot is identified, the first question is where it went. If the data has gaps, the manufacturer either over-recalls and absorbs enormous cost, or under-recalls and risks affected product reaching customers. The cost of the recall is often dwarfed by the cost of not knowing how far it reaches.
Manufacturers use Qualytics to validate the integrity of traceability data at every link in the chain. Checks confirm that supplier lot numbers are complete on receipt, map cleanly to internal lot codes, carry required attributes into batch records, and tie quality results to the correct batch. Cross-source reconciliation catches the gaps that break a trace, such as a lot that appears in receiving but never in production, or a batch record missing the data that should close the loop. These checks run continuously, so the trace is ready before a recall forces the question.
Trusting shop-floor metrics like OEE and SPC
Production data drives every shop-floor metric a plant manager relies on, including Overall Equipment Effectiveness, Statistical Process Control, yield, and scrap. When that data is wrong, the metrics are wrong, and so are the decisions made from them.
The failure modes are familiar to any plant. Downtime reason codes are recorded inconsistently across shifts, so the metric shows a problem no one can diagnose. Sensor data has gaps during critical windows, leaving open whether a process stayed in spec. Scrap quantities do not reconcile between the production system and finance. Shift counts do not roll up to the daily total. Improvement efforts stall in arguments about whether the number is even real.
Manufacturers use Qualytics to validate production data as it lands, with checks for completeness of expected parameters, consistency of downtime taxonomies, plausibility of sensor readings, timeliness of arrival, and reconciliation between shift counts, daily totals, and finance. Auto-inferred rules establish a baseline from historical patterns, so a new gap, an unexpected scrap divergence, or a shifted downtime distribution surfaces as a finding rather than an end-of-month surprise.
Scaling data quality across a federated manufacturer
A large manufacturer rarely operates as one company. It runs as several business segments, each with its own P&L, leadership, and technical leads sitting inside the business rather than in central IT. That structure creates a specific data quality problem: the central team cannot write every check for every segment, lacking both the headcount and the domain knowledge, and the moment a segment has to file a ticket and wait, adoption stalls.
Manufacturers use Qualytics to operationalize shared ownership across segments without sacrificing centralized governance. Business teams, data teams, and the systems consuming the data work from one governed foundation. The central team profiles a segment's data and the platform surfaces a starting set of checks automatically, covering completeness, uniqueness, ranges, freshness, and cross-field consistency. The segment's technical lead inherits that starter set and tunes it, keeping what fits, archiving what does not, and adding the domain-specific rules the central team would never have known to write. Role-based access keeps each segment to its own data, and tagging routes findings to the segment that owns the source.
The central team's role shifts from authoring every check to owning the platform and rolling quality signals up to leadership. For any manufacturer with M&A history or independent business units, this federated model is the only durable way to scale data quality across a portfolio.
Manufacturers use Qualytics to enforce trust at scale
Across manufacturing, the pattern is consistent. Data quality failures do not announce themselves. They weaken inventory accuracy, production metrics, and regulatory evidence while automation and AI continue operating as if nothing has changed.
Qualytics enforces trust before data is used for inventory and procurement decisions, production reporting, regulatory filings, or AI-driven systems. As data reuse and decision velocity accelerate, proactive data quality has become a core manufacturing control, not a technical afterthought.
For how the same approach plays out in other data-intensive industries, see how insurance companies and asset managers operationalize data quality with Qualytics.
Book a demo to see how manufacturers operationalize data quality across their most critical use cases.
Chapters
Related Articles

Data Quality vs Data Control: Why AI Demands Controls
AI removes the human safety net that contained bad data. The data control layer validates data at the moment it's acted on.
.png)
How Augmented Data Quality Turns Detection into Governance Outcomes
Three enterprise teams used AI-augmented data quality findings to build durable governance controls. Here's how they did it.
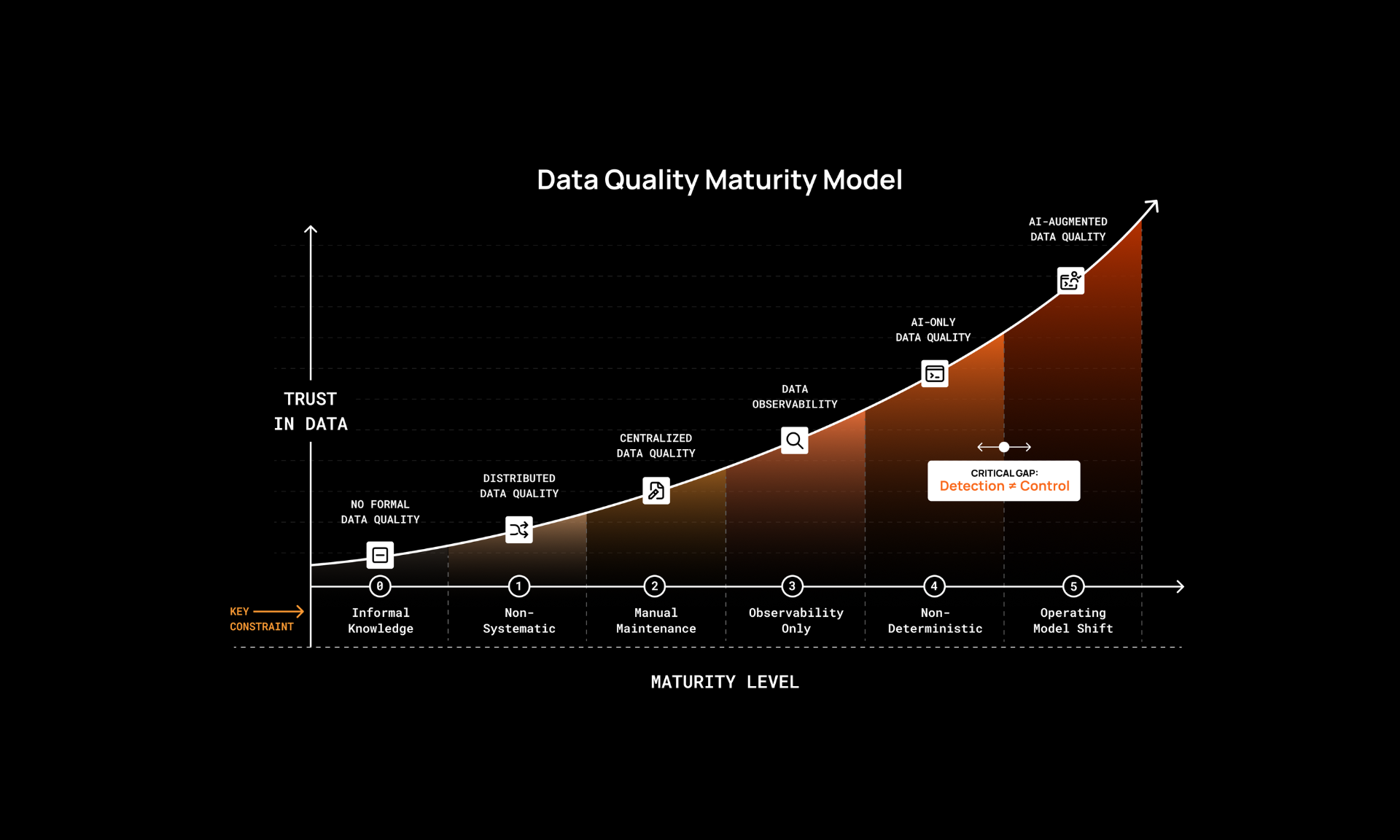
The Data Quality Maturity Model: Moving from Incident Response to Proactive Data Trust
A framework outlining how organizations evolve data quality into proactive, governed control across complex data environments.
Related News
Data Quality vs Data Control: Why AI Demands Controls
AI removes the human safety net that contained bad data. The data control layer validates data at the moment it's acted on.
How Augmented Data Quality Turns Detection into Governance Outcomes
Three enterprise teams used AI-augmented data quality findings to build durable governance controls. Here's how they did it.
The Data Quality Maturity Model: Moving from Incident Response to Proactive Data Trust
A framework outlining how organizations evolve data quality into proactive, governed control across complex data environments.
