A framework outlining how organizations evolve data quality into proactive, governed control across complex data environments.

Mar 19, 2026
10
min read
Table of Contents
Score your data quality program across seven dimensions. See your maturity level, where gaps exist, and whether your data supports AI.

Most organizations don’t neglect data quality intentionally. They begin by embedding validations into code, add centralized rules as incidents accumulate, and adopt new monitoring tools as reliance on data increases. Each step improves visibility and control. Yet over time, these approaches don’t keep pace with growing data volume, evolving business definitions, and expanding stakeholder expectations.
The underlying challenge is not effort, but scalability. Methods that work for a handful of datasets become difficult to sustain across hundreds. Detection may improve, but ownership, maintenance, and enforcement are fragmented. As analytics programs mature and AI moves from pilots to production, the cost of inconsistent standards becomes much higher and more visible. Copilots and agents retrieve, combine, and act on context at machine speed, which means bad data drives automated decisions and cross-system workflows before anyone has a chance to intervene.
The Data Quality Maturity Model clarifies this progression and outlines the common stages organizations move through as data ecosystems become more complex with more sources, users, and use cases. The model evaluates not only whether issues can be detected, but how systematically teams define acceptable behavior, maintain standards over time, and enforce remediation in production.
It also establishes a direct connection between data quality maturity and AI readiness. Copilots and agents retrieve, combine, and act on context at machine speed, which means bad data drives automated decisions and cross-system workflows before anyone has a chance to intervene. Organizations that cannot govern data quality as a proactive control system are not prepared to trust AI systems with their data.
Organizations may progress through these levels non-linearly. Maturity is not defined by tool adoption alone, but by the ability to sustain trust in data as scale, automation, and business impact continue to expand.
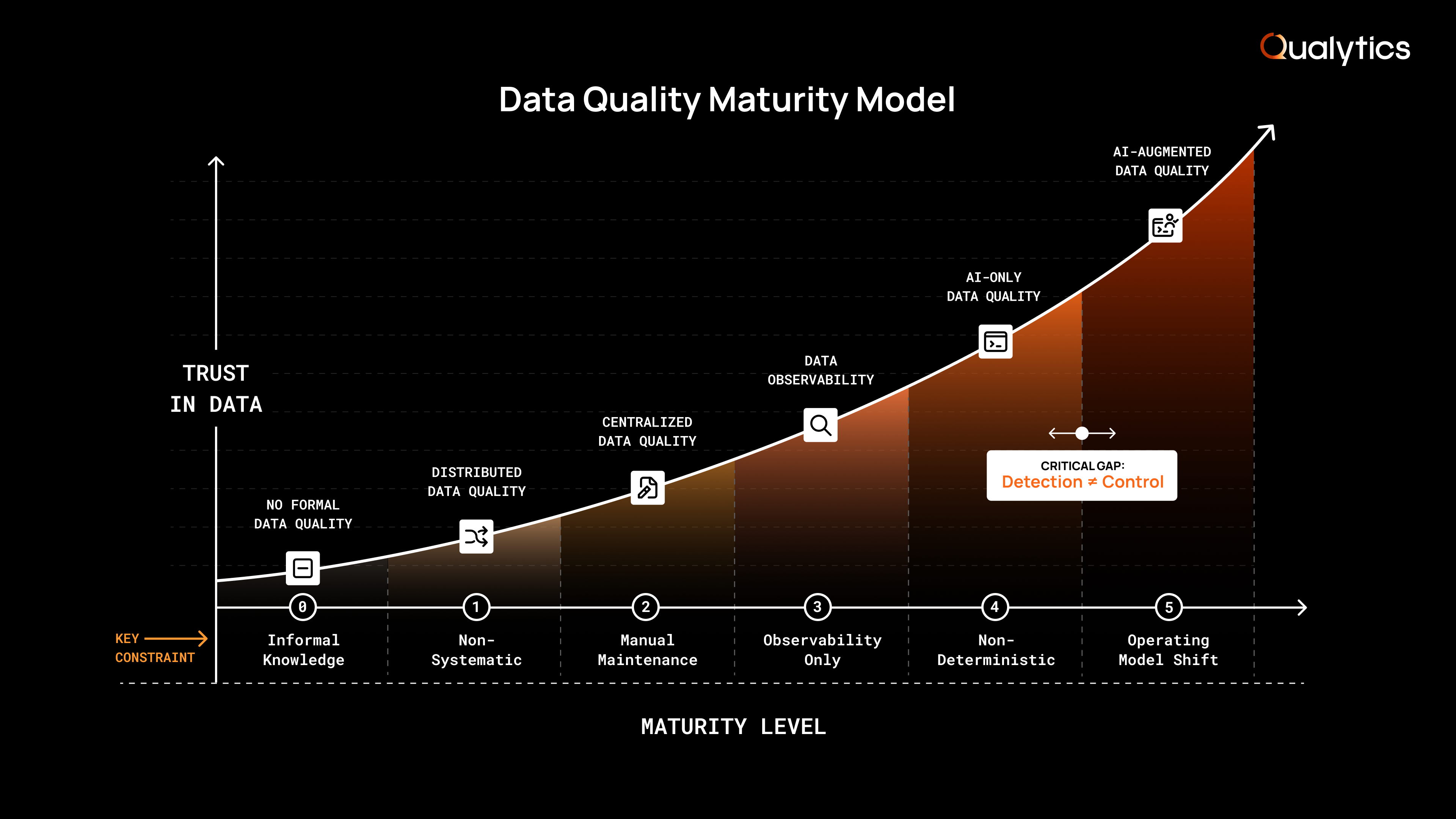
Level 0: No Formal Data Quality
Issues are identified only after business impact
At this level, there is no intentional data quality practice. Issues surface only when someone in the business sees a number that “can’t be right.” The response is incident-driven and inherently reactive: identify who owns the data, investigate what changed, apply a one-time fix, and move on.
Occasionally, a one-off check is added in a specific system or report, usually in the form of a report filter, SQL snippet, buried in an existing Python script, or manual reminder, to prevent the exact issue from recurring. More often, the knowledge stays informal and undocumented, and the organization relies on a small number of people to notice and troubleshoot problems as they appear. This creates fragile dependencies and inconsistent responses, where similar issues are resolved differently and root causes aren’t addressed systematically.
What this really means
- No defined standards for acceptable data behavior
- No systematic detection or monitoring
- Ownership is informal and inconsistent
- Issues are addressed only after impact
Primary limitations
- Recurring issues are not prevented
- Institutional knowledge is undocumented and fragile
- Root causes are rarely addressed structurally
- Trust depends on individual vigilance rather than process
- AI systems consuming this data have no quality signals to reason on, making any automated decision inherently unreliable
Reality: Data quality is accidental rather than intentional, and business decisions rely on data that has not been systematically validated.
Level 1: Distributed Data Quality
Basic validations embedded directly in code
At this level, teams move beyond informal troubleshooting and begin embedding data validation directly into SQL queries, Python scripts, or transformation frameworks such as dbt. These are typically written after a specific issue has occurred and are designed to prevent that exact failure from recurring.
Over time, dozens or even hundreds of validations accumulate across repositories, dashboards, and pipelines. However, they remain distributed and tightly coupled to the code that produced them. Definitions of acceptable behavior exist within individual pipelines or repositories, but they are not formalized as shared standards across teams.
Coverage expands incrementally, driven by engineering capacity and frequency of incidents rather than systematic discovery of risk. Validations focus on known failure cases, while unknown risks remain unaddressed.
What this really means
- Validation logic is embedded in code, not centrally governed
- Coverage grows case by case, not systematically
- Ownership is informal and primarily technical
- Business stakeholders have little visibility into data quality validations
Primary limitations
- Manual validation authoring does not scale
- Coverage remains uneven and incomplete
- Logic is brittle and dependent on individual contributors
- Issues are still identified after impact has occurred
- AI systems inherit the same coverage gaps and blind spots as the validations themselves, with no mechanism to flag what hasn't been checked
Reality: Basic safeguards are introduced, but data quality is fragmented, engineer-driven, and reactive to past incidents.
Level 2: Centralized Data Quality
Deterministic rules governed but fully human-authored
At this level, organizations formalize data quality by adopting a centralized platform. Validations are no longer scattered across repositories; instead, deterministic rules are defined, stored, and monitored within a dedicated system of record. Governance becomes more structured, and visibility into rule coverage improves.
This level introduces structure and formal accountability, replacing distributed code-level validations with a centralized governance model. However, rule creation and maintenance remain entirely manual and human-driven. Each rule must be explicitly authored, configured, tested, and updated as data structures, upstream systems, and business definitions evolve. Like in level 1, rules are only prioritized after issues are discovered in downstream systems.
As data ecosystems grow, rule volume expands into the thousands or tens of thousands. Maintenance becomes the dominant workload, as teams continuously update thresholds, adjust logic for schema changes, and reconcile rule drift as the business evolves—and maybe they will remember to update associated documentation of rule logic. In large programs, sustaining rule coverage requires sizable teams of full-time contributors focused primarily on upkeep rather than expanding protection.
Because rule authoring and maintenance require strong SQL and data engineering expertise, this work remains concentrated within highly specialized technical teams. Business stakeholders rarely participate directly in rule refinement, reinforcing a separation between business context and technical enforcement.
Centralization improves control and visibility. But without automation in rule generation and lifecycle management, scalability remains constrained by human capacity.
What this really means
- A centralized system of record for deterministic data quality rules
- Explicit standards defined and maintained by technical teams
- Rule maintenance becomes a significant ongoing operational burden
- Business context and technical enforcement remain loosely connected
Primary limitations
- Manual rule authoring and maintenance become the primary bottleneck
- Coverage expands only as fast as specialized teams can sustain it
- Rules fall behind as data models and business logic change
- Business users remain dependent on technical intermediaries
- Rule maintenance bottlenecks prevent coverage from keeping pace with AI systems that consume data faster than teams can write rules for it
Reality: Centralization improves governance structure, but human-authored rule management doesn’t scale proportionally with data growth or organizational complexity.
Level 3: Data Observability
Visibility into pipeline health and system reliability
At this level, organizations introduce data observability to monitor the operational health of their data systems. Pipelines and data systems are tracked continuously for freshness, volumetrics, and system performance. Teams gain visibility into whether data is arriving on time, in the expected structure, and at the expected scale.
This represents an important step forward in reliability. Failures that previously went unnoticed are detected more quickly, and engineering teams can usually respond before downstream systems break.
However, observability focuses on how data moves through systems, not whether the data itself is correct, complete, or fit for business use. It answers questions like:
- Did the data arrive on time?
- Did the schema change?
- Did row counts deviate from expectations?
It does not answer:
- Is this KPI calculated correctly?
- Does this value violate a business policy?
- Is this dataset aligned with regulatory requirements?
As a result, organizations improve technical reliability without fundamentally changing how business standards are defined, enforced, or governed.
What this really means
- Strong visibility into pipeline and system health
- Faster detection of operational failures
- Alerts primarily routed to engineering teams
- Limited business context attached to signals
Primary limitations
- No mechanism to encode acceptable business behavior
- Detection remains technical rather than policy-driven
- Remediation workflows are not standardized or governed
- Business stakeholders remain outside quality enforcement
- Observability signals confirm data arrived but cannot tell an AI system whether that data is correct, complete, or fit for its intended use
Reality: Pipeline failures are detected earlier, but assessment of data correctness still depends on downstream interpretation.
Level 4: AI-Only Data Quality
Black-box anomaly detection without explicit rules
At this level, organizations address the limitations of data observability by adopting a model-driven data quality platform. With observability alone, pipeline health may be strong, but business users still surface issues in metrics, reporting logic, or downstream applications.
To close the gap between operational reliability and data quality, a model-driven platform automatically profiles datasets and detects statistical anomalies. Rather than manually defining every deterministic rule, these platforms rely on black-box anomaly detection to analyze historical behavior and deviations across fields and metrics. Coverage expands significantly, including issues that were never explicitly anticipated.
This shift represents an advancement in detection capability. Unknown risks are more likely to surface, and signal generation scales far beyond what centralized data quality can achieve.
However, model-based anomaly detection does not, by itself, define acceptable business behavior. Signals indicate that something changed, but they don’t inherently identify whether that change violates a documented policy, KPI definition, or regulatory requirement. Additionally, because these models are probabilistic and opaque in how thresholds are derived, the rationale behind an alert is not always directly tied to an explicit, documented business rule.
When anomaly detection broadens across datasets and metrics, signal volume increases substantially. Without predefined standards and governed remediation workflows embedded into the system, detection may scale fast without organizational ability to consistently evaluate and enforce remediations, inevitably leading to alert fatigue and ignored anomalies.
What this really means
- Broad, automated detection of statistical deviations
- Reduced need for manual rule authoring
- Signals require interpretation before enforcement
- Governance and remediation remain partially manual
Primary limitations
- Acceptable behavior is not explicitly defined
- Anomalies must be interpreted before ownership and action are assigned
- Remediation workflows are not inherently policy-driven
- Consistent auditability and enforcement remain difficult
- AI systems consuming this data receive detection signals but no governed standards to act on, making autonomous decision-making unreliable
Reality: Detection becomes scalable, but governance and enforcement remain dependent on human coordination rather than embedded policy.
Level 5: AI-Augmented Data Quality
Automated rule lifecycle with human oversight, ownership, and governed context at time of use
At this level, organizations move beyond automated detection and establish an operating model where automation and human oversight work together to define, enforce, and continuously refine explicit data standards across the enterprise. Automated profiling and AI-assisted rule generation provide broad initial coverage, while domain experts validate intent, clarify business meaning, and retain accountability for outcomes.
Crucially, automation not only handles rule creation but also rule maintenance. As data models evolve, upstream systems change, or business definitions shift, rules are automatically monitored, recalibrated, and updated with human review where necessary. This proactivity prevents rule drift from becoming a structural bottleneck and keeps data quality aligned with the business over time.
Rules are versioned, explainable, and treated as durable governance artifacts. Each rule has defined ownership, documented purpose, and an associated remediation pathway. When violations occur, response is initiated through governed workflows rather than ad hoc coordination. Detection, ownership, and enforcement scale together as an integrated system.
Why this level is the prerequisite for AI readiness
Copilots and agents don't always follow predefined pipeline paths. They retrieve, combine, and act on data dynamically, often without human review, and at machine speed. When the data they act on is poor quality, bad outputs compound across workflows and automated decisions faster than any manual process can catch, leading to incorrect calculations feed downstream reports, flawed context drives automated actions, and errors propagate across systems before anyone has a chance to intervene.
This requires a validate-at-use model: data quality that’s evaluated and applied as a control at the point of use, not just at predefined checkpoints. Quality scores, anomaly history, and governed rules must be available wherever data is consumed, so systems can proceed, flag, or block based on governed thresholds before a decision is made.
Only an augmented data quality foundation supports this. AI-only detection (Level 4) generates signals but lacks the explicit standards and governed workflows needed to function as a control layer. Manual approaches and observability alone cannot maintain standards at the scale and speed AI systems require. At Level 5, data quality operates as a shared control layer where humans, copilots, and agents all reason from the same governed foundation.
Organizations don’t reach this point without deliberate shifts in ownership, governance, and operating model. The defining characteristic is not simply more automation, but the integration of automation + human oversight, explicit policy, and shared accountability into a sustainable enterprise control system.
What this really means
- Automated profiling and AI-assisted rule generation establish 95%+ coverage from the start
- Quality signals function as real-time controls available to humans, copilots, and agents alike
- Updates and recalibrations are continuously maintained through augmentation
- Business and technical stakeholders share accountability for defined standards
- Explicit, versioned standards are treated as governance artifacts, not isolated checks
- Ownership is attached to policy, not inferred after incidents
- Remediation is initiated through structured, traceable workflows
What changes
- Rules evolve alongside changes in models and business logic
- Prevention is embedded upstream rather than triggered by downstream discovery
- AI systems access governed context at the point of use, enabling trusted automation at enterprise scale
- Enforcement becomes policy-driven rather than interpretive
- Data quality scales without linear increases in manual effort
Reality: Data quality shifts from a detection function into a governed control system that scales with the business and serves as the prerequisite for trustworthy AI.
Maturity Is About Control, Not Detection
Data quality maturity is not measured by how many alerts an organization can generate or how many rules it can write. It is measured by how consistently it can establish clear standards for data behavior, maintain those standards as systems evolve, and enforce remediation before business impact occurs.
Many organizations make meaningful progress as they move from distributed validations to centralized governance and from manual rule writing to automated anomaly detection. Each stage improves visibility, but visibility alone does not guarantee control.
As data environments scale and AI systems begin acting on data autonomously, the cost of inconsistent standards becomes increasingly visible. A wrong number in a report is a relatively contained problem. A wrong number consumed by an agent that triggers a workflow, updates a system of record, or makes a financial decision is a compounding one that may never be reviewed by a human. The window between data error and business impact, which once gave teams time to investigate and intervene, shrinks to zero when machines are making automated decisions.
Detection is table stakes. The real differentiator is whether data quality operates as a governed control system that combines automation with human oversight, maintains policies proactively, and applies quality as a control at the point data is used. Validate-at-use, where data is evaluated against governed standards at the moment it drives a decision, is what separates organizations that can trust their AI systems from those that cannot.
Organizations do not advance through these stages simply by adopting new tools. Maturity reflects a shift in operating model. The goal is not to eliminate every error. It is to build a system in which data quality functions as a control layer that serves humans and AI systems from the same governed foundation.
Chapters
Related Articles
Qualytics Introduces the Data Control Layer for Trusted Context
AI systems depend on context, but context without control creates risk. Qualytics introduces the data control layer that enables trusted data at the moment it is used.

From Firefighting to Foresight: Building Trust Through Augmented Data Quality
Move from reactive cleanup to proactive trust. Here’s how augmented data quality empowers Chief Data Officers with trusted, AI-ready enterprise data.

Top Data Quality Trends for 2026: Data Trust in the Age of AI
Five data quality trends shaping 2026, and how enterprises must evolve to govern AI-driven decision execution responsibly.
Related News
Qualytics Introduces the Data Control Layer for Trusted Context
AI systems depend on context, but context without control creates risk. Qualytics introduces the data control layer that enables trusted data at the moment it is used.
From Firefighting to Foresight: Building Trust Through Augmented Data Quality
Move from reactive cleanup to proactive trust. Here’s how augmented data quality empowers Chief Data Officers with trusted, AI-ready enterprise data.
Top Data Quality Trends for 2026: Data Trust in the Age of AI
Five data quality trends shaping 2026, and how enterprises must evolve to govern AI-driven decision execution responsibly.
