Qualytics introduces native validation for nested JSON, arrays, and structs, enabling comprehensive data quality checks without costly flattening pipelines.

Mar 16, 2026
5
min read
Table of Contents
Working with nested JSON or semi-structured data?
See how Qualytics expands data quality coverage without manual flattening.

Introducing native validation for nested data in Qualytics
Validating semi-structured data is one of the hardest challenges in modern data quality.
Events arrive as nested JSON. Orders include arrays of line items. User records contain multiple addresses, devices, and preferences. While lakehouses make it easy to store this data, validating it reliably is much harder.
Most teams face a frustrating tradeoff:
- Spend engineering time flattening nested data into relational tables, or
- Accept blind spots in nested fields
Today we’re introducing a new capability in Qualytics that removes that tradeoff.
Qualytics can now profile and validate semi-structured data directly, including arrays, structs, and arrays of structs—without requiring manual flattening.
The Hidden Cost of Flattening Nested Data
One of the toughest challenges we hear from customers is validating nested data structures.
A good example comes from MAPFRE, one of the world’s largest insurance companies. Their systems ingest quote data as complex JSON payloads containing deeply nested structures.
To run data quality checks, the team estimated they would need to manually flatten the data into relational tables—a project that would require nearly 3,000 engineering hours.
Working together, we reduced that effort by 98%. But that raised a bigger question:
What if teams didn’t have to flatten nested data at all?
That question led us to build native support for validating semi-structured data in Qualytics.
Customer Example: MAPFRE
MAPFRE processes quote data delivered as complex nested JSON documents.
Before using Qualytics, validating that data required flattening the JSON payloads into relational tables so traditional quality checks could run. This meant building transformation pipelines to explode arrays, project nested fields, and maintain staging tables for validation.
The engineering team estimated this effort would require approximately 3,000 hours of development work, along with ongoing maintenance whenever schemas changed.
Using Qualytics, MAPFRE was able to profile and validate the nested structures directly without building flattening pipelines.
This reduced the engineering effort required for validation by 98%, while expanding quality coverage across nested fields that previously went unchecked.
Why Semi-Structured Data Is Difficult to Validate
Semi-structured data introduces complexity because validation must occur at multiple levels of the data structure.
Structs
A struct is a column that contains multiple named subfields.
Example:
address = {
street: "123 Main St",
city: "Boston",
zip: "02108"
}
Validating address is not null is very different from validating:
address.zip exists
address.zip matches a valid format
In practice, the validations with the greatest downstream impact occur at the child-field level.
Arrays
Arrays introduce another layer of complexity because validation must occur at two levels:
- the array container
- the elements inside the array
For example, a line_items array might be:
- null
- present but empty
- populated but incorrect because one or more elements contain invalid values
Arrays of Structs
Arrays of structs combine both challenges.
Example:
payments = [
{ method: "card", amount: 50 },
{ method: "card", amount: 25 }
]
Validation rules may involve relationships between fields:
if payments[*].method = "card"
then payments[*].card_last4 must exist
Or set-level constraints:
no duplicate payments[*].auth_code
sum(payments[*].amount) = order_total
To enforce these rules, engineers typically have to:
- explode arrays into rows
- validate element records
- aggregate results
- reconcile results back to the parent record
This is why validating nested data traditionally requires flattening pipelines.
The Tradeoff Most Teams Face
In practice, teams usually make one of two compromises.
Option 1: Flatten Everything
Engineers create views or staging tables so nested fields behave like normal columns.
While effective, this approach introduces:
- significant engineering effort
- fragile transformations
- ongoing maintenance when schemas evolve
Option 2: Accept Partial Coverage
Teams validate top-level scalar fields such as:
- primary keys
- timestamps
- status codes
Nested fields—often where the most critical issues occur—remain unchecked.
Examples include:
address.zipline_items.price- cross-element validations within arrays of structs
Real-World Example: Detecting Revenue Errors in Nested Order Data
Consider an e-commerce platform storing order records as Parquet files in Amazon S3.
Each order contains an array of line items:
order_id: 84231
line_items: [
{ sku: "SKU-100", quantity: 2, price: 50 },
{ sku: "SKU-204", quantity: -1, price: 30 }
]
The data pipeline ran successfully. There were no schema errors or missing records. But monthly financial reports began showing understated revenue. The issue was buried inside the nested line_items array.
A recent upstream migration introduced a logic error in returns processing. Instead of generating separate return records, the system wrote returned items as negative quantities inside existing orders.
Using Qualytics, the team profiled the files without flattening them.
Nested fields were automatically surfaced, including:
customer.country
line_items.sku
line_items.quantity
line_items.price
Qualytics inferred validation rules such as:
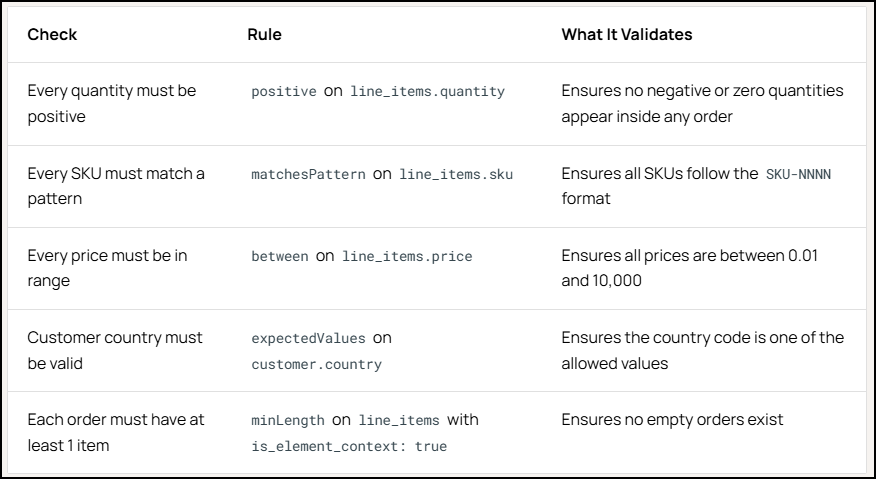
On the next scan, the platform flagged:
- 23 orders with negative quantities
- 4 orders with invalid SKU formats
The issue was quickly traced to the upstream migration, and the checks now run automatically on every file.
Flattening Pipelines vs Native Nested Validation
When teams need to validate nested data, they typically build flattening pipelines to transform arrays and structs into relational tables.
Traditional Approach
Raw JSON / Parquet
│
ETL pipeline
│
explode arrays
│
flatten structs
│
create staging tables
│
run quality checks
Challenges:
- additional engineering pipelines
- fragile schema transformations
- validation happens after transformation
- nested data coverage is incomplete
Qualytics Approach
Raw JSON / Parquet
│
Qualytics profiling
│
automatic schema traversal
│
nested fields discovered
│
rules inferred and monitored
Benefits:
- no flattening views or staging tables
- immediate nested field coverage
- resilience to schema evolution
- faster anomaly detection
How Qualytics Validates Nested Data
Qualytics automatically traverses nested schemas during profiling and surfaces child field paths as explicit subfields.
Each nested field receives:
- its own profile
- its own quality checks
- its own quality score
For arrays of structs, each projected field becomes its own array column and receives both container-level and element-level validation.
Traversal is recursive up to a configurable depth, and generated field names follow the schema’s path notation.
The full nested schema is visible in the datastore explorer, where a hierarchical field tree makes complex structures easy to explore.

Simplifying Array Validation
Qualytics separates array validation into two contexts.
Container level checks.
- Not Null: Is the array column not null?
- Not Empty: Does the array have at least one element?
- Min / Max Length: Does the array have the expected number of elements?
Element level checks.
- Not Null: Is every element in the array not null?
- Not Empty: Does every element have a value?
- Min / Max Length: Does each element have the expected length?
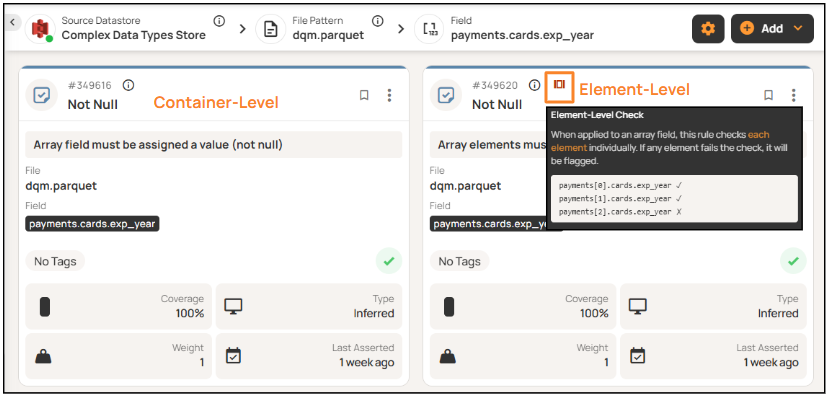
The platform automatically distinguishes between container-level and element-level validation when applying rules.
Faster Root Cause Analysis
When an anomaly occurs, Qualytics displays the failing record in its original nested structure.
Instead of reconstructing payloads with explode queries or flattening views, teams can inspect raw nested values directly.
This makes it easier to determine whether an issue originated from:
- the data producer
- an ingestion mapping
- an upstream transformation

By preserving the original structure, Qualytics shortens the path from anomaly detection to root cause resolution.
What This Unlocks for Data Teams
Native validation of semi-structured data changes how teams approach data quality.
Broader data quality coverage
Teams can validate nested fields that were previously skipped, including:
- child fields inside structs
- element values inside arrays
- relationships within arrays of structs
Less engineering overhead
Without flattening pipelines, teams avoid building and maintaining:
- transformation views
- staging tables
- explode-and-reconcile pipelines
This reduces both implementation time and ongoing operational complexity.
Faster incident resolution
Because Qualytics surfaces nested failures directly in their original structure, engineers can identify root causes faster. Instead of rebuilding payloads with custom queries, teams can inspect failing records immediately.
More Coverage Without Flattening
Semi-structured data has traditionally forced teams to choose between engineering effort and incomplete coverage.
Qualytics removes that tradeoff.
The platform provides profiling, rule inference, and monitoring for structs, arrays, and arrays of structs without requiring additional transformation pipelines.
Teams gain:
- broader coverage across nested data
- reduced operational overhead
- faster anomaly detection
- simpler maintenance as schemas evolve
Get Started
Already a Qualytics customer?
Complex data type support is available today. Learn more in our user guide.
Working with nested JSON or semi-structured data?
Request a demo to see how Qualytics expands data quality coverage without manual flattening.
Chapters
Related Articles
What We Delivered in 2025 to Empower Data Quality Teams in 2026
A look at the ten Qualytics features shipped in 2025, built to help data quality teams operate at scale and support AI, governance, and analytics.
How to Detect Table and Schema Changes in Snowflake Using Time Travel
This use case demonstrates how a Qualytics customer developed a lightweight monitoring process utilizing Snowflake Time Travel and Qualytics Quality Checks to surface data and schema changes within minutes, without requiring the addition of new pipelines or infrastructure.
.png)
Trusted AI and Analytics at Scale with Databricks and Qualytics
AI-augmented data quality on Databricks, delivering proactive profiling, scalable rules, continuous monitoring, and governed remediation for trusted analytics and AI.
Related News
What We Delivered in 2025 to Empower Data Quality Teams in 2026
A look at the ten Qualytics features shipped in 2025, built to help data quality teams operate at scale and support AI, governance, and analytics.
How to Detect Table and Schema Changes in Snowflake Using Time Travel
This use case demonstrates how a Qualytics customer developed a lightweight monitoring process utilizing Snowflake Time Travel and Qualytics Quality Checks to surface data and schema changes within minutes, without requiring the addition of new pipelines or infrastructure.
Trusted AI and Analytics at Scale with Databricks and Qualytics
AI-augmented data quality on Databricks, delivering proactive profiling, scalable rules, continuous monitoring, and governed remediation for trusted analytics and AI.
