Note
These notes catch up with several since our last published update on 2024.6.18 and are current as of the 2024.6.29 version of the platform.
Feature Enhancements
Computed Field Support
- Introduced computed fields allowing users to dynamically create new virtual fields within a container by applying transformations to existing data.
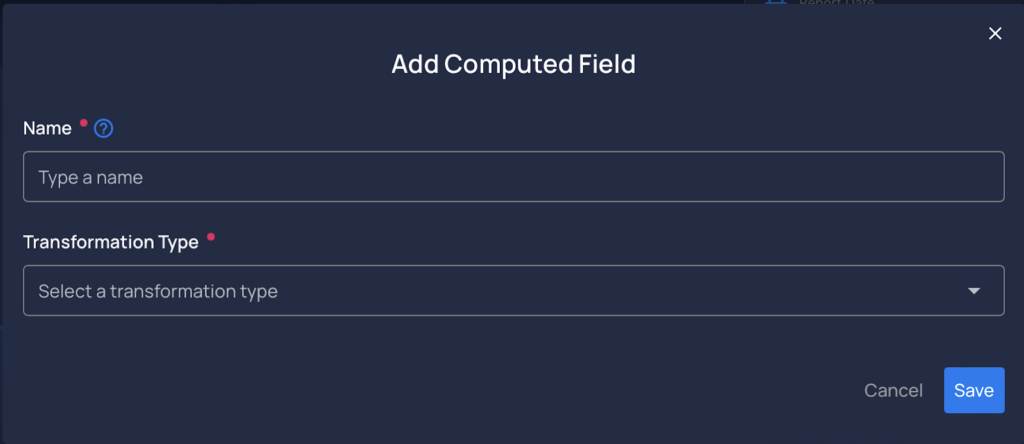
- Computed fields offer three transformation options to cater to various data manipulation needs. Each transformation type is designed to address specific data characteristics
- Cleaned Entity Name: Automates the removal of business signifiers such as ‘Inc.’ or ‘Corp.’ from entity names, simplifying entity recognition.
- Convert Formatted Numeric: Strip formatting like parentheses (for negatives) and commas (as thousand separators) from numeric data, converting them into a clean, numerically-typed format.
- Custom Expression: Allows users to apply any valid Spark SQL expression to combine or transform fields, enabling highly customized data manipulations.
- Users can define specific checks on computed fields to automatically detect anomalies during scan operations.
- Computed fields are also visible in the data preview tab, providing immediate insight into the results of the defined transformations.
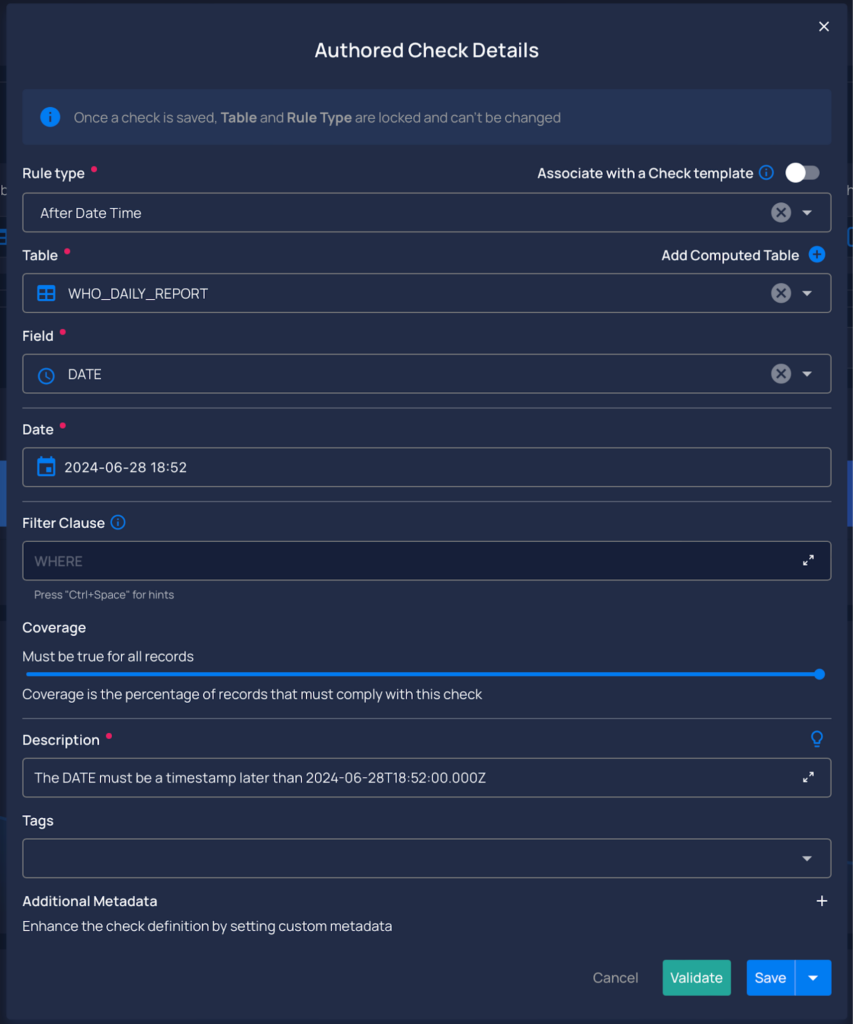
Autogenerated Descriptions for Authored Checks
- Implemented an auto generation feature for check descriptions to streamline the check authoring process. This feature automatically suggests descriptions based on the selected rule type, reducing manual input and simplifying the setup of checks.
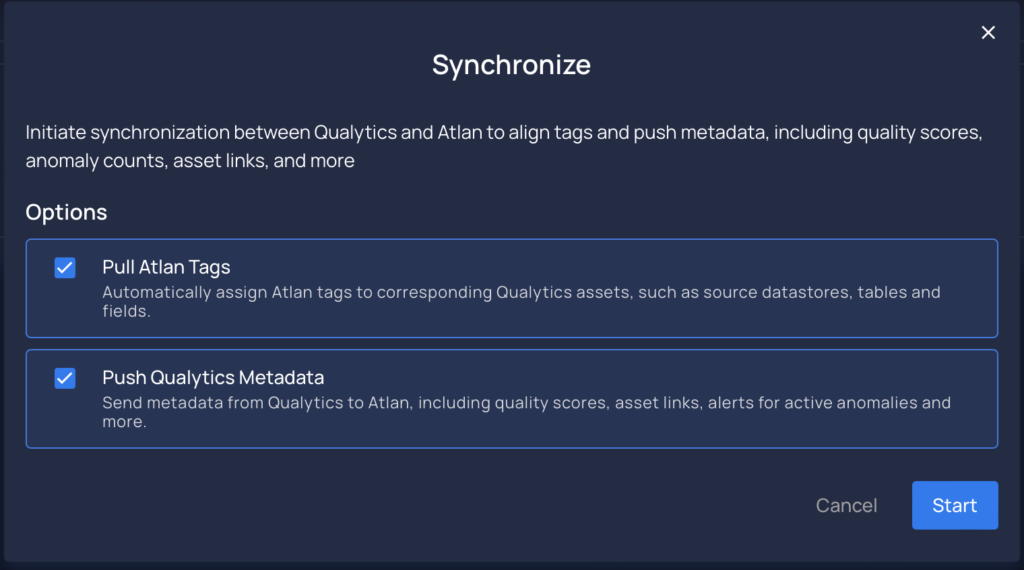
Event-Driven Catalog Integrations and Sync Enhancements
- Enhanced the Atlan integration and synchronization functionalities to include event-driven support, automatically syncing assets during Profile and Scan operations. This update also refines the Sync and Integration dialogs, offering clearer control options and flexibility.
Sorting by Anomalous Record Count
- Added a new sorting filter in the Anomalies tabs that allows users to sort anomalies by record count, improving the manageability and analysis of detected anomalies.

Refined Tag Sorting Hierarchy
- Updated the tag sorting logic to consistently apply a secondary alphabetical sort by name. This ensures that tags will additionally be organized by name within any primary sorting category.
General Fixes
- Profile Operation Support for Empty Containers
- Resolved an issue where profiling operations failed to record fields in empty containers. Now, fields are generated even if no data rows are present.
- Persistent Filters on the Explore Page
- Fixed a bug that caused Explore to disable when switching tabs on the Explore page. Filters now remain active and consistent, enhancing user navigation and interaction.
- Visibility of Scan Results Button
- Corrected the visibility issue of the ‘results’ button in the scan operation list at the container level. The button now correctly appears whenever at least one anomaly is detected, ensuring users have immediate access to detailed anomaly results.
- General Fixes and Improvements
As usual, our User Guide and accompanying Change Log captures more details about this release.